

Ringkasan
Permainan tebak kata “Wordle” memiliki daftar kata yang dapat dianalisis untuk mendapatkan kata tebakan awal yang tepat. Analisis data menggunakan bahasa R berhasil menemukan perkiraan kata yang paling dapat membantu menyelesaikan permainan. Meski bukan pendekatan yang akurat, hasil analisis ini cukup memberikan gambaran mengenai penggunaan probabilitas kemunculan huruf dalam menentukan kualitas tebakan. Tautan github: https://github.com/fajarfh/analisis-wordle
Pendahuluan
Sebagai latihan agar lebih terbiasa dengan bahasa R untuk analisis data, saya mencoba mereproduksi proyek Wordle Data Analysis oleh Arthur Holtz untuk menemukan kata terbaik dalam mengawali tebakan di game Wordle. Meski game tersebut saat ini sudah tidak viral lagi, tapi saya rasa analisis ini masih cukup berguna untuk belajar R.
Wordle adalah permainan web menebak kata 5 huruf Bahasa Inggris dalam 6 kesempatan. Setiap huruf yang digunakan dalam tebakan akan ditandai jika ada dan posisnya tepat, ada tapi posisinya keliru, atau tidak ada sama sekali dalam kata jawaban. Ini akan membantu pemain untuk memilih kata tebakan selanjutnya.
Selain itu, hanya ada 1 sesi permainan dan 1 jawaban per hari. Artinya, pemain tidak boleh gagal dalam 6 kesempatan karena jawabannya tidak akan diulang besoknya. Pemain juga mendapat statistik yang menunjukkan ketepatannya dalam menebak.
Pertanyaan yang ingin dijawab oleh analisis ini adalah, bagaimana agar kita mahir dalam bermain Wordle?
Secara umum, ‘mahir’ dalam permainan ini adalah bisa menebak dalam sesedikit mungkin kesempatan, dan kata tebakan pertama yang tepat akan membantu untuk itu. Meski demikian, menemukannya, dan mendefinisikannya, tidaklah sesederhana itu. Menemukan kata yang tepat ini memerlukan eksplorasi dengan menelusuri data daftar kata yang digunakan Wordle.
Target
Dalam proyek ini, ada beberapa output spesifik yang ingin saya dapatkan:
- Mengasah kemahiran menggunakan R
- Mendapatkan kata yang paling tepat sebagai tebakan awal
Penyimpangan dari Reproduksi
Meski mayoritas analisis dan pengolahan data yang saya lakukan adalah ‘mencontek’ atau reproduksi dari pekerjaan Arthur Holtz dalam artikel, saya melakukan beberapa perubahan pada code R yang digunakan. Banyak ide-ide yang muncul dan secara intuitif dirasa lebih baik serta lebih pantas dicoba. Ada juga perubahan dalam sumber data atau perbedaan environment pemrograman yang mengharuskan modifikasi.
Perubahan-perubahan ini akan disampaikan pada bagian yang relevan.
Kode pemrograman R yang dihasilkan akan berbeda dengan Arthur, tapi kode yang dia buat sangat membantu dalam memulai pemrograman.
Sumber Data
- Daftar kata yang digunakan oleh Wordle.
Wordle tidak menggunakan seluruh kosakata dalam bahasa Inggris. Wordle memiliki daftar kata tersendiri dalam bentuk array String yang bisa ditemukan di: https://www.nytimes.com/games-assets/v2/wordle.1bc05d595206395cbc0c.js - Data jawaban-jawaban yang pernah keluar.
Untuk daftar kata yang pernah menjadi jawaban, saya menggunakan data dari: List of Past Wordle Answers & Archive (Updated Daily) (yourdictionary.com)
Saya asumsikan data pada sumber tersebut dapat dipercaya karena jawaban terakhir sesuai dengan yang saya mainkan. Data ini jawaban Wordle mulai dari 19 Juni 2021.
Proses Analisis
Proyek ini tidak mengikuti tahapan analisis dengan runut (Ask/Tanya, Prepare/Siapkan, Process/Olah, Analyze/Analisis, Share/Bagikan, dan Act/Tindakan) karena sifatnya eksploratif; pertanyaan akan berubah sewaktu-waktu saat menemukan insight baru dalam data. Selain itu, proses pengambilan, pengolahan, analisis, dan visualisasi data dilakukan oleh pemrograman R dalam satu rangkaian kode yang dieksekusi langsung sehingga tahapan menjadi tidak perlu dipisahkan secara kaku.
Dalam pemrograman yang dibuat, rangkaian instruksi diurutkan dari penyiapan library, pengambilan data, pengolahan data, serta analisis dan visualisasi data. Terdapat fungsi-fungsi moduler yang dapat digunakan untuk melakukan analisis tertentu lewat konsol R pada RStudio.
Sebagai catatan, semua fungsi pemrograman ditulis agar bisa digunakan untuk tipe permainan yang berbeda misalnya Wordle dengan 6 huruf atau bahasa lain. Karenanya fungsi-fungsi akan dimodifikasi sesuai kebutuhan sehingga berbeda dengan yang ditulis Arthur yang jadi referensi.
Menyiapkan Library
Kode ini saya salin dari yang dibuat Arthur dengan sedikit modifikasi. Semuanya sudah mencakup pemanggilan library-library yang diperlukan untuk menjalankan fungsi-fungsi built-in yang diperlukan dalam analisis.
# Memanggil library yang diperlukan tanpa
# menampilkan pesan pada konsol
suppressMessages({
library(httr)
library(dplyr) #penting untuk menggunakan pipeline
library(stringr)
library(ggplot2)
library(ggthemes)
library(scales)
library(tidyr)
library(venn) #untuk membuat diagram venn
})Pengumpulan Data
Arthur menggunakan data daftar kata langsung dari Wordle, yang saat ini struktur datanya sudah berbeda. Karenanya, kode untuk mengambil dan membersihkan data perlu dimodifikasi. Saya juga menggunakan data jawaban-jawaban yang pernah muncul di Wordle, yang disediakan oleh WordFinder.
Daftar Kata dari Wordle
Daftar kata yang digunakan pada Wordle diambil menggunakan kode pada R agar data yang diambil selalu up to date untuk mengantisipasi kalau-kalau ada penambahan kata baru dalam daftar. Saya menggunakan kode yang sama seperti pada replikasi. Meski alamat URL-nya sudah berubah, source code berkas ini masih dapat diakses.
# Extract data daftar kata dari situs Wordle
# note: daftar kata ini sebenarnya ada dua:
# -Berurut dari a - z (aahed - zymic);
# daftar kata yang bisa ditebak tapi tidak akan
# jadi jawaban. Pembuktiannya, daftar kata ini
# tidak beririsan dengan daftar jawaban
# dari WordFinder (ada 2 pengecualian)
# -Daftar acak setelah zymic (cigar - augur);
# daftar kata yang bisa jadi jawaban dan dipilih
# secara acak tiap hari buat jadi jawaban harian
url1 = "https://www.nytimes.com/games-assets/v2/wordle.1bc05d595206395cbc0c.js"
wordle_script_text = GET(url1) %>%
content(as = "text", encoding = "UTF-8")Proses tersebut mengunduh keseluruhan source code pada alamat yang dituju, yang berupa berkas JavaScript, dalam variabel string wordle_script_text. Tentunya kita tidak memerlukan seluruh source code, hanya yang memuat daftar kata saja. Namun untuk mengidentifikasi daftar kata tersebut, saya perlu menemukannya secara manual.
Setelah ditelisik, daftar kata pada Wordle disimpan dalam sebuah array berisi sekitar 14.855 kata. Namun sebenarnya daftar kata tersebut terbagi menjadi dua:
- Daftar kata yang bisa digunakan sebagai tebakan, tapi tak akan jadi jawaban. Daftar ini merupakan kata yang valid dalam Bahasa Inggris namun tidak lumrah atau berupa bentuk plural dari suatu kata. Posisinya berada di awal array dan disusun secara alfabetis mulai dari “aahed” hingga “zymic”.
- Daftar kata yang bisa jadi jawaban. Daftar ini dimulai dari kata “cigar” yang terletak setelah kata “zymic” hingga akhir array. Daftar disusun secara acak dan tidak menunjukkan bahwa urutannya menunjukkan urutan kemunculannya sebagai jawaban dalam permainan. Hal ini bisa diketahui dengan membandingkannya dengan daftar jawaban dari WordFinder. Namun pada awal-awal daftar, terlihat bahwa urutannya sesuai dengan urutan kemunculan sebagai jawaban. Jumlah kata-kata ini adalah 2.309.
Untuk keperluan analisis ini, saya membuat dua set data dengan menggunakan fungsi substr() pada wordle_script_text untuk mengambil bagian dari source code yang mengandung daftar kata tertentu. Karena seluruh kata disusun dalam array, pengambilan data dapat dilakukan dengan lebih mudah.
- Data pertama adalah keseluruhan daftar kata untuk analisis tambahan. Patokannya adalah nama variabel array dan tanda kurung siku pada awal array (“la=[”) hingga akhir array yang ditandai dengan kurung siku tutup dan variable setelahnya (“],ol”). Keputusan mengambil sampai akhir array dan tidak berpatok pada kata terakhir (“augur”) adalah untuk mengantisipasi kalau-kalau ada kata baru ditambahkan di akhir array.
Ini menghasilkan data keseluruhan kata yang dapat digunakan untuk menebak pada Wordle termasuk yang tidak bisa dipakai untuk jawaban dan pernah menjadi jawaban. Data ini saya beri namaall_wordle_list. - Data kedua adalah datar kata yang bisa jadi jawaban. Daftar kata ini menjadi sumber data utama yang akan dianalisis. Daftar ini saya ambil dengan berpatokan pada kata “cigar” dan akhir array (sama seperti data pertama). Data ini saya beri nama
wordle_list.
Pengambilan Data Pertama: Seluruh Daftar Kata Wordle
Fungsi substr() memerlukan input berupa angka yang menunjukkan posisi awal dan akhir dari string yang akan diambil. Untuk itu saya menggunakan fungsi str_locate() yang memberikan angka posisi dari deretan karakter atau kata yang patokan. Karena patokan ada yang berupa simbol atau karakter spesial, saya perlu menggunakan aturan regex (regular expression) agar simbol tersebut tidak dianggap bagian dari sintaks fungsi. Untuk panduan dari aturan regex yang digunakan, saya mengacu pada artikel ini: A Guide to R Regular Expressions With Examples | DataCamp.
Dalam menggunakan str_locate(), saya juga perlu mendefinisikan apakah angka posisi yang diinginkan berada di awal patokan atau di akhir patokan. Penambahan parameter +1 atau -1 juga digunakan untuk mendapatkan angka posisi yang lebih pas.
Hasil dari proses substr() akan menghasilkan string daftar kata yang dipisahkan oleh tanda koma. Fungsi str_split() dapat mengubah string tersebut menjadi list dalam satu kolom. Namun sebelumnya, string tersebut perlu dibersihkan menggunakan fungsi str_remove_all() untuk menghilangkan karakter garis miring yang juga muncul setelah proses substr(). List hasil str_split() diubah menjadi data frame agar lebih mudah diolah, diganti nama kolomnya, dan kemudian isinya dijadikan huruf kapital semua agar seragam.
Berikut kode pembuatan data all_wordle_list:
# Mengambil bagian daftar kata (seluruhnya) dari sumber Wordle
all_wordle_list = substr(
wordle_script_text,
# ambil dari nama variabel dalam script yang memuat daftar kata
# yaitu "ia=[". Mulai dari bracket di ujungnya (end) ...
(str_locate(wordle_script_text, "(ia\\=\\[)")[,"end"]+1),
# ...sampai nama variabel setelah bracket penutup daftar kata
# yaitu "],la". Ambil bracket di awalnya (start) antisipasi
# jika kata-nya bertambah. Dikurangi 1 agar pas.
(str_locate(wordle_script_text, "(],la)")[,"start"]-1)) %>%
data_bersih()Fungsi data_bersih di atas dipisahkan dalam satu fungsi karena diperlukan baik saat membuat all_wordle_list maupun wordle_list. Fungsi ini membersihkan masing-masing data dari karakter atau simbol yang tak perlu, dan menyeragamkan kapitalisasi hurufnya.
Fungsi ini ditulis sebelum kode pembuatan data lewat substr() agar bisa dieksekusi pada kode di atas.
# Fungsi membersihkan data hasil substr pada data
# Harus ditulis sebelum eksekusi substr
data_bersih = function(daftar_kata){
data_baru = daftar_kata %>%
str_remove_all("\"") %>%
str_split(",") %>%
data.frame() %>%
select(kata = 1) %>%
mutate(kata = toupper(kata))
return(data_baru)
}Output dari kode pembuatan data all_wordle_list adalah variabel data berisi 14.855 kata. Hasil berdasarkan data pada 16 Juni 2023.
Pengambilan Data Kedua: Daftar Kata Jawaban Wordle
Dengan cara yang mirip dan fungsi-fungsi yang sama, kita akan mengambil data daftar kata jawaban pada Wordle atau wordle_list. Kode pengambilan datanya adalah sebagai berikut:
# Mengambil bagian daftar kata jawaban dari sumber Wordle
# dimulai dari "cigar" sampai akhir.
wordle_list = substr(
wordle_script_text,
# Tidak ada pembatas yang jelas antara "zymic" dan "cigar" jadi
# lokasi awal substr dimulai dari awal (start) kata "cigar"...
(str_locate(wordle_script_text, "cigar")[,"start"]),
# ...sampai nama variabel setelah bracket penutup daftar kata
# yaitu "],la". Ambil bracket di awalnya (start) antisipasi
# jika kata-nya bertambah.Dikurangi 1 agar pas.
(str_locate(wordle_script_text, "(],la)")[,"start"]-1)) %>%
data_bersih()Output dari kode ini adalah data wordle_list yang berisi 2.309 kata. Hasil berdasarkan data pada 16 Juni 2023.
Daftar Kata Jawaban dari WordFinder
Untuk memperoleh daftar kata-kata jawaban lama dari Word Finder, saya menggunakan kode yang sama seperti saat mengambil daftar kata dari Wordle tentunya dengan alamat yang berbeda. Di sini ada hal yang tidak terlalu saya pahami karena tidak seperti saat mengunduh daftar kata Wordle, saya tidak menuliskan URL hingga ke nama berkas-nya. Namun, proses tersebut menghasilkan kode berkas HTML dalam satu variabel string.
# Extract data daftar kata jawaban lama dari Wordfinder
# Hasil yang benar muncul jika url tidak mengacu pada
# laman/file spesifik (mis: index.html)
url2 = "https://wordfinder.yourdictionary.com/wordle/answers/"
answer_script_text = GET(url2) %>%
content(as = "text", encoding = "UTF-8")Daftar kata jawaban tertuliskan dua kali pada berkas HTML tersebut: satu dalam bagian Head dan satu lagi di bagian Body. Pada tampilan laman web WordFinder yang memuat jawaban Wordle tersebut, jawaban Wordle memang ditampilkan dalam tabel-tabel yang dipisah per bulan.
Kata-kata ini tidak tersimpan dalam array seperti saat mengambil daftar kata dari Wordle sehingga lebih sulit jika menggunakan substr() untuk mengambil data yang diinginkan.
Namun, daftar kata pada bagian Head memiliki struktur seperti tabel atau entri data JSON yang memiliki sufiks. Dengan kata lain, setiap kata yang akan diambil pasti diawali karakter tertentu yang pada kasus ini adalah “answer=/”. Karenanya saya menggunakan fungsi str_extract_all() yang dapat mengambil seluruh kata dengan pola tertentu dalam data string.
Fungsi yang saya gunakan akan mengambil setiap kata yang diawali kata “answer” lalu diikuti sejumlah karakter simbol lalu diikuti oleh kata apapun, yang dalam kasus ini adalah kata jawaban 5 huruf yang ingin kita ambil. Saya menggunakan aturan regex yang sama sepertis sebelumnya. Untuk proses pembersihannya tidak menggunakan fungsi data_bersih() karena format output dari proses ekstraksi dan ‘pengotor’ dalam data tersebut berbeda.
# Mengambil bagian daftar kata jawaban lama dari sumber WordFinder
# Ambil kata yang diawali "answer\", deretan symbol setelahnya
# (regex \\W+), dan 1 kata string normal setelahnya (regex \\w+)
answer_list = str_extract_all(answer_script_text,
'(answer\\\\\\W+\\w+)') %>%
data.frame() %>%
select(kata = 1) %>%
mutate(kata = str_replace(kata,'answer\\\\":\\\\"', ""))Output dari kode ini adalah data answer_list yang isinya per hari artikel ini ditulis (16 Juni 2023) adalah 728 kata. Jumlah kata akan bertambah tiap hari.
Validasi Sumber Data
Sekarang kita memiliki 3 data berisi kata-kata 5 huruf yang masing-masingnya berada dalam variabel bertipe list dengan hanya 1 kolom.
Selanjutnya saya ingin memvalidasi bahwa semua kata pada wordle_list benar-benar tidak memuat kata yang tidak bisa jadi jawaban. Karenanya, saya melakukan operasi difference antara all_wordle_list dengan wordle_list yang menghasilkan daftar kata yang tidak bisa menjadi jawaban, kemudian melakukan intersection/irisan antara data tersebut dengan answer_list.
Jika hasilnya 0, maka kita telah memvalidasi bahwa kata pada all_wordle_list minus kata pada wordle_list tidak mengandung kata-kata yang pernah menjadi jawaban. Dengan kata lain, kata pada answer_list pasti seluruhnya ada di wordle_list. Jika valid, console akan menampilkan teks “OK”.
# Pengecekan kata jawaban lama pada daftar kata Wordle
# yang tidak bisa jadi jawaban
checking_list = intersect(setdiff(all_wordle_list, wordle_list), answer_list)
if(count(checking_list)==0) {
cat("OK")
rm(checking_list)
}Catatan: Per 16 Juni 2023, ada 2 kata yang tidak masuk di wordle_list tapi ada di all_wordle_list dan answer_list. Dengan kata lain, ada jawaban yang tidak diambil dari wordle_list tapi diambil dari all_wordle_list. Untuk memudahkan analisis, kita asumsikan bahwa 2 kata ini hanya outlier dan kata-kata yang mungkin jadi jawaban tetap diambil hanya dari wordle_list.
Daftar Kata Jawaban Tersisa
Setelah data di atas valid, kita perlu membuat daftar kata jawaban tanpa jawaban lama. Hal ini dilakukan dengan melakukan operasi difference atau menggunakan fungsi setdiff() antara wordle_list dengan answer_list sehingga menghasilkan data exclude_list. Data ini mengandung kata jawaban yang belum pernah muncul, sehingga akan memberikan analisis yang lebih akurat.
# Membuat daftar kata jawaban yang belum pernah muncul;
# Alias daftar kata dari Wordle yang belum ada di WordFinder
exclude_list = setdiff(wordle_list, answer_list)Per 16 Juni 2023, data ini berisi 1.584 kata.
Analisis
Seperti yang disebut pada pendahuluan, kita ingin mencari kata tebakan pertama yang paling tepat agar bisa memenangkan permainan dengan lebih cepat. Dengan kata lain, kata yang membantu menjawab dengan jumlah tebakan paling sedikit.
Hal yang perlu diingat adalah bahwa dalam Wordle, baik tebakan benar maupun salah dapat memberikan kita informasi. Jadi, meski kata tebakan pertama tidak benar, kata yang tepat dapat mempermudah tebakan selanjutnya.
Apa definisi dari kata yang tepat? Sebenarnya, sulit untuk menentukannya. Arthur menggunakan teknik brute force untuk memvalidasi kualitas kata tebakan dengan sistem penilaian. Namun saya rasa ada cara yang lebih matematis untuk menjawab hal ini.
Ide awalnya adalah dengan menemukan huruf yang paling sering muncul dalam daftar kata. Dengan kata lain, menghitung frekuensi dan probabilitasnya (frekuensi dibagi jumlah data) sehingga kata yang mengandung huruf tersebut bisa dibilang jadi kata terbaik.
Setelah menjelajahi beberapa hipotesis, asumsi, dan pengujian untuk mengembangkan ide itu, ada beberapa hal yang saya temukan:
- Pilihan kata jawaban harian pada Wordle sangat acak, sehingga mustahil dapat memperkirakan kata tebakan pertama yang langsung benar.
- Kita dapat menghitung probabilitas atau jumlah kemunculan suatu huruf dalam daftar kata baik dalam posisi bebas maupun dalam posisi huruf tertentu.
- Probabilitas atau jumlah kemunculan huruf seperti di atas harus dihitung berdasarkan data daftar kata jawaban yang belum pernah muncul (
exclude_list) agar lebih akurat menggambarkan kemungkinan huruf yang muncul dalam jawaban. - Kata dalam daftar seluruh kata yang bisa dijadikan tebakan pada Wordle (
all_wordle_list) bisa jadi kata yang tepat meski tidak mungkin jadi jawaban. - Probabilitas kemunculan huruf (p(huruf)) bisa dihitung, tapi kemunculan huruf dalam daftar kata bersifat co-dependent. Artinya, probabilitas kemunculan huruf “A” pada kata yang mengandung “C” (p(A|C)) tidak sama dengan probabilitas huruf “C” pada kata yang mengandung “A” (p(C|A)). Akibatnya, sulit melakukan analisis dengan mengolah data probabilitas masing-masing huruf saja. Akan lebih logis untuk menghitung probabilitas pada masing-masing kasus kemunculan huruf sesuai dengan data daftar kata yang ada. Dengan kata lain, untuk menghitung probabilitas kemunculan huruf “A” dan “C” (p(A|C)), kita tidak menghitungnya dengan: p(A) x p(C). Melainkan, menyaring daftar kata dengan huruf “A” dan “C”, menghitung jumlahnya, dan membaginya dengan jumlah seluruh kata.
- Probabilitas kata mengandung 5 huruf yang benar, terlepas posisinya tepat attau tidak, meski mudah dihitung pada dasarnya juga tidak perlu dihitung karena bisa kita bayangkan nilainya sangat kecil dan tidak relevan dengan tujuan analisis.
Melihat temuan-temuan di atas nampaknya mencari kata terbaik dengan menghitung probabilitas kemunculan huruf cukup intuitif dan matematis. Namun poin 5 dalam temuan di atas agak memperumit situasinya. Menemukan kata terbaik yang mengandung huruf yang paling banyak muncul jadi kurang intuitif karena meski misal kita menemukan 5 huruf terbanyak, kata yang mengandung huruf tersebut belum tentu ada.
Akan lebih akurat jika kita menganalisis setiap kata dalam daftar dan menghitung kemungkinan salah satu, dua, atau kelima huruf yang dimilikinya muncul dalam jawaban. Itu mungkin dilakukan, namun mengevaluasi 14.000-an kata (berdasarkan data all_wordle_list) memerlukan resource komputasi yang besar dan tidak dapat dicukupi oleh laptop yang saya gunakan.
Karenanya, dalam analisis ini saya tetap mencari beberapa kata terbaik dengan mencari kata dengan huruf-huruf terbanyak. Kata-kata ini akan dievaluasi lebih lanjut dengan menghitung ‘nilai’ kemungkinan kemunculan salah satu satu, dua, hingga kelima hurufnya dalam jawaban sehingga dari kata-kata yang ditemukan akan dipilih yang paling baik.
Secara intuitif, dapat dibayangkan bahwa kata-kata seperti itu merupakan:
- Kata yang dibentuk oleh huruf-huruf yang paling banyak digunakan dalam daftar kata, dan/atau
- kata yang tiap posisinya diisi oleh huruf yang paling sering muncul pada posisi tersebut dalam daftar kata
Mengenai detail penghitungannya akan dijabarkan pada bagian masing-masing.
Dengan mempertimbangkan hal-hal di atas, maka tahapan analisis adalah sebagai berikut:
- Mencari huruf yang paling banyak digunakan dalam daftar kata
exclude_list - Mencari huruf yang paling banyak digunakan dalam daftar kata
exclude_listper posisi huruf - Menemukan kata yang berpotensi memiliki probabilitas tinggi
- Validasi dengan menghitung probabilitas kemunculan huruf pada kata-kata dari poin 3
1 – Huruf yang Paling Sering Muncul
Pada referensi Arthur, huruf terbanyak dihitung dengan menghitung semua huruf pada daftar. Semua kata dipecah jadi huruf-huruf dan daftar kata diubah menjadi daftar huruf. Jumlah masing-masing huruf kemudian dihitung.
Menurut saya, ini kurang relevan jika ingin mencari probabilitas suatu huruf ada dalam suatu kata baik pada posisi tertentu maupun bebas posisi. Terlebih suatu kata dapat mengandung dua huruf yang sama atau lebih dan ini dapat mengecoh dalam analisis.
Yang kita perlu ketahui adalah: apakah suatu huruf ada dalam suatu kata? Maka yang perlu dihitung adalah jumlah kata yang menggunakan huruf “A”, bukan jumlah huruf “A” dalam daftar kata.
Menghitung Persentase Huruf dalam Daftar Kata
Untuk itu, saya membuat fungsi persen_huruf() yang menghitung persentase kemunculan huruf, menyimpannya dalam tabel data, dan mengurutkannya untuk mengetahui huruf dengan jumlah kemunculan terbanyak. Dalam fungsi ini, semua huruf alfabet dicek keberadaannya dan dihitung dalam semua kata pada daftar_kata. Dalam analisis ini, daftar_kata adalah parameter fungsi yang nantinya akan diisi dengan exclude_list. Huruf yang digunakan lebih dari sekali dalam suatu kata akan tetap dihitung satu.
Setelah dihitung, jumlah atau frekuensi kemunculan tiap huruf langsung dibuatkan persentase dan dimasukkan ke dalam tabel secara berurutan dari yang terbanyak.
# Fungsi menghitung jumlah penggunaan huruf di tiap kata
persen_huruf = function(daftar_kata){
# Membuat data frame kosong untuk menampung daftar persentase
persentase_huruf = data.frame(huruf=character(), persen=double())
# Menguji semua huruf dalam alfabet
# dan menghitung jumlah kata yang mengandung huruf tersebut
for(i in LETTERS){ #loop untuk semua karakter alfabet
# Langsung menghitung jumlah kata dengan filter huruf alfabet
hitung = count(filter(daftar_kata, grepl(i, unlist(daftar_kata[1]))))
persentase = 100*hitung/count(daftar_kata) #hitung persentase
# Memasukkan data huruf ke kolom pertama
# dan data persentase ke kolom kedua
# Saat memasukkan data huruf, sekalian membuat baris baru
persentase_huruf[nrow(persentase_huruf)+1,1] = i
persentase_huruf[nrow(persentase_huruf),2] = persentase
}
# Data disusun berdasarkan persentase terbesar
return(arrange(persentase_huruf,desc(persen)))
}Visualisasi untuk Membantu Analisis
Untuk lebih memahami mengenai huruf terbanyak yang muncul dalam daftar kata, kita bisa membuat grafik batang melalui fungsi plot_persen() berikut. Fungsi ini memiliki parameter untuk mengubah warna grafik dan judulnya.
# Fungsi membuat plot grafik dengan skala persen
# Parameter input utama adalah letter_list yang merupakan
# data persentase huruf output dari persen_huruf()
plot_huruf = function(letter_list, judul, subjudul, warna){
# Variabel untuk membantu penghitungan dan tampilan grafik:
frek = unlist(letter_list[2]) #Data nilai persen
huruf0 = unlist(letter_list[1]) #Data huruf
# Menyesuaikan skala sumbu Y dengan data dan
# memastikan semua label skala tampil dalam sumbu Y
balance_max = ifelse(max(frek) < 20, 2, 5)
maxscale = max(frek)+(balance_max - max(frek) %% balance_max)
# Patokan untuk posisi label berdasarkan nilai data
patokan = maxscale*0.25
# Bagian utama plotting grafik
# Definisi area plot dan label sumbu x,y
print(ggplot(letter_list,
aes(x = reorder(huruf0, (-frek)), y = frek)) +
# Definisi isi data dan warna grafik
geom_bar(fill = warna,
stat = 'identity') +
# Definisi label data, posisinya berubah dari dalam batang
# ke luar batang jika nilainya terlalu kecil
# nilai persen dibulatkan ke 1 angka desimal
geom_text(aes(label = sprintf("%1.1f%%", frek)),
vjust = 0.5,
hjust = if_else(frek < patokan, 1, 0),
size = 4,
nudge_x = 0.1,
nudge_y = if_else(frek < patokan,
0.06*patokan,
-0.06*patokan),
angle = 270)+
# Definisi skala pada sumbu Y
scale_y_continuous(labels = sprintf("%1.0f%%",
pretty(frek)),
breaks = pretty(frek),
expand = c(0,0),
limits = c(0,maxscale)) +
# Tema dan teks lainnya pada area plot
theme_clean() +
xlab("Huruf") +
ylab("Persentase") +
labs(caption = "Terinspirasi dari Arthur Holtz\nlinkedin.com/in/arthur-holtz/") +
ggtitle(judul, subtitle = subjudul))
}
Fungsi Menghitung Persentase Huruf dan Membuat Plot
Selanjutnya, agar dapat menghitung frekuensi huruf dan langsung membuat plot, fungsi-fungsi di atas dimasukkan dalam fungsi utama persen_plot() sebagai berikut:
# Fungsi menghitung frekuensi huruf
# dan langsung plotting grafik
persen_plot = function(daftar_kata, judul, subjudul, warna){
# Memanggil fungsi membuat persentase huruf
persentase_huruf = persen_huruf(daftar_kata)
# Membuat grafik dari persentase
# output langsung dalam file PNG
ggsave(
paste0(deparse(substitute(daftar_kata))
,"_bebas.png"),
plot_huruf(persentase_huruf, judul, subjudul, warna),
width = 7,
height = 5,
dpi = 180
)
# Agar tampilan data pada tabel lebih mudah dibaca
persentase_huruf[,2] = round(persentase_huruf[,2],
digits = 2) %>%
format(nsmall = 2) %>%
paste0("%")
# Data disusun berdasarkan persentase terbesar
return(arrange(persentase_huruf,desc(persen)))
}Berikut ini hasil eksekusi fungsi tersebut di R console menggunakan data exclude_list melalui sintaks:
persen_plot(exclude_list, "Persentase Kemunculan Huruf dalam Kata", "Dari daftar kata jawaban yang belum pernah muncul", "lightblue")(Hasil berdasarkan data pada 16 Juni 2023)
Hasil Plot:
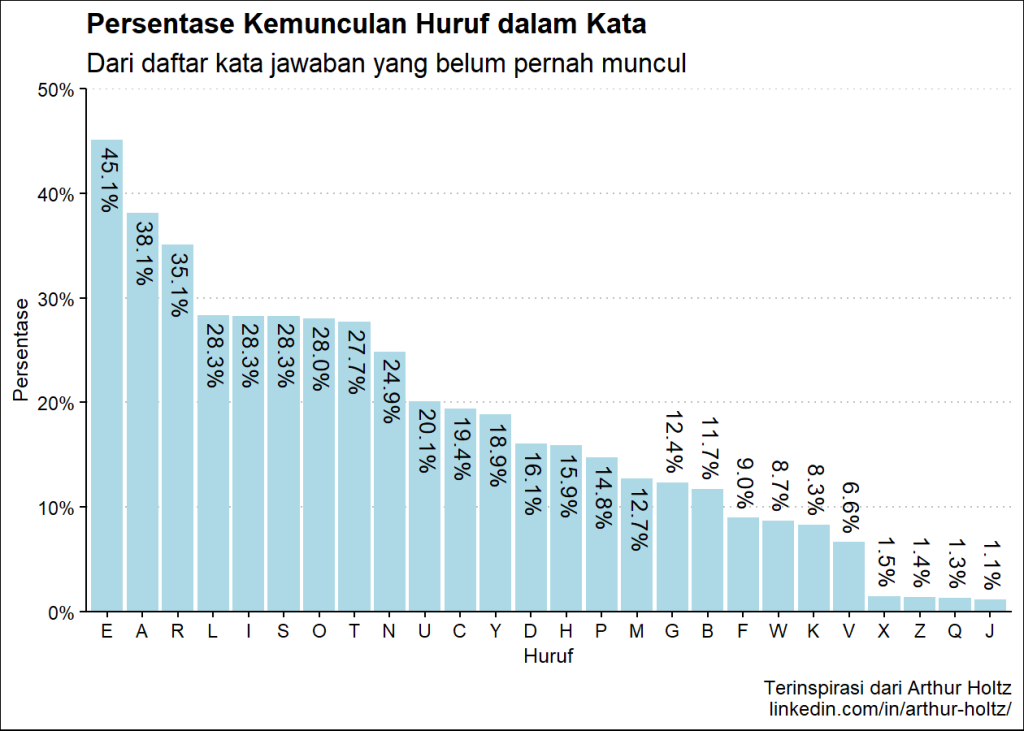
Hasil pada console:
huruf persen
1 E 45.14%
2 A 38.13%
3 R 35.10%
4 L 28.35%
5 I 28.28%
6 S 28.28%
7 O 28.03%
8 T 27.71%
9 N 24.87%
10 U 20.14%
11 C 19.44%
12 Y 18.88%
13 D 16.10%
14 H 15.91%
15 P 14.77%
16 M 12.69%
17 G 12.37%
18 B 11.74%
19 F 8.96%
20 W 8.71%
21 K 8.33%
22 V 6.63%
23 X 1.45%
24 Z 1.39%
25 Q 1.33%
26 J 1.14%Dari hasil penghitungan di atas, dapat diketahui dengan jelas bahwa huruf E, A, R, I, dan L adalah 5 huruf yang paling banyak digunakan dalam daftar kata exclude_list.
2 – Huruf yang Paling Sering Muncul per Posisi
Tahap kedua analisis adalah menghitung frekuensi huruf pada posisi huruf pertama hingga terakhir. Untuk menghitungnya, saya mengikuti cara yang dilakukan Arthur.
Penghitungan didahului dengan mengubah tabel data daftar kata dari 1 kolom kata menjadi 5 kolom huruf. Setiap kolom mewakili posisi huruf dalam kata. Kemudian, frekuensi kemunculan huruf untuk tiap kolom/posisi akan dihitung.
Memecah Kolom Kata Menjadi Kolom Huruf
Proses pengubahan 1 kolom kata menjadi 5 kolom huruf dilakukan dengan menggunakan fungsi separate(). Proses keseluruhan transformasi data ini dieksekusi dalam fungsi pecah_kata() berikut ini:
# Fungsi memecah daftar kata jadi daftar huruf per posisi;
# Memisahkan tiap huruf ke kolom masing-masing
pecah_kata = function(daftar_kata){
# Memastikan kata yang dievaluasi merupakan data frame
# agar bisa diolah lebih lanjut
if(!is.data.frame(daftar_kata)){
daftar_kata = data.frame(kata = c(daftar_kata))
}
# Menghitung panjang kata
# Dengan ini, fungsi bisa digunakan untuk kata selain 5 huruf
# Kata yang diambil hanya kata teratas saja yang dapat
# mewakili kata-kata lain pada daftar
huruf_per_kata = str_length(daftar_kata[1,1])
# Memisahkan huruf-huruf ke kolom
# Perhatikan bahwa fungsi separate menghasilkan
# 1 kolom kosong di awal yang akan dihapus lewat "select(-1)"
# karenanya, parameter "into = "
# diisi seakan kita memisahkan 1 kolom jadi 6
letter_list = daftar_kata %>%
separate(kata, sep = "",
into = as.character(1:(huruf_per_kata+1)), ) %>%
select(-1)
# Menyeragamkan nama kolom
for(i in 1:huruf_per_kata) {
new_name = paste0("No",i)
names(letter_list)[i] = new_name
}
# Mengirimkan data kata yang sudah dipecah
return(letter_list)
}Perhatikan bahwa fungsi ini dapat dipakai juga untuk memecah daftar kata yang tidak terdiri dari 5 huruf, selama jumlah huruf per kata seragam dalam daftar kata.
Jika fungsi ini dijalankan dengan parameter exclude_list, maka hasilnya akan seperti ini:
(Hasil berdasarkan data 16 Juni 2023)
Sintaks: pecah_kata(exclude_list)
Sebelumnya:
kata
<chr>
1 POOCH
2 HIPPY
3 FOLLY
4 LOUSE
5 GULCH
6 VAULT
7 GODLY
8 THREW
9 FLEET
10 GRAVE
Setelah pecah_kata():
No1 No2 No3 No4 No5
<chr> <chr> <chr> <chr> <chr>
1 P O O C H
2 H I P P Y
3 F O L L Y
4 L O U S E
5 G U L C H
6 V A U L T
7 G O D L Y
8 T H R E W
9 F L E E T
10 G R A V E
Fungsi Menghitung Persentase Huruf
Selanjutnya, jumlah kemunculan huruf di tiap posisi dihitung dengan membuat tabel summary. Fungsi ini langsung menghitung nilai persentasenya. Algoritma untuk menghitung persen di sini berbeda dengan persen_huruf(). Di sini kita tidak mengecek keberadaan huruf dalam suatu kata lalu menjumlahkannya dalam daftar kata, namun menghitung jumlah suatu huruf di tiap kolom.
Dalam fungsi persen_huruf_posisi() ini, terdapat parameter colnum dengan nilai default 1 agar bisa dipakai untuk menghitung persentase huruf pada posisi yang berbeda. Jadi menjalankan fungsi ini sekali hanya akan menghitung persentase huruf pada 1 kolom atau satu posisi huruf saja.
# Fungsi menghitung huruf dalam 1 kolom;
# kolom dikelompokkan dalam huruf,
# dihitung persentasenya dan diurutkan
# berdasarkan persentase terbesar
persen_huruf_posisi = function(daftar_kata, colnum = 1){
letter_list = daftar_kata %>%
select(huruf = all_of(colnum)) %>%
group_by(huruf) %>%
# persen = 100 * frek/jumlah baris
summarize(persen = 100*n()/nrow(daftar_kata)) %>%
arrange(desc(persen)) %>%
data.frame()
# Mengirimkan data persentase
return(letter_list)
}Fungsi Menghitung Persentase Huruf per Posisi dan Membuat Plot
Fungsi pecah_kata(), persen_huruf_posisi(), dan plot_huruf() digunakan dalam satu fungsi yang dapat memecah daftar kata menjadi huruf, menghitung jumlah huruf per posisi, dan membuatkan visualisasi dalam satu perintah. Fungsi ini saya namakan persen_plot_posisi().
# Fungsi menghitung persentase huruf per posisi
# dan langsung membuat grafik masing-masing posisi
persen_plot_posisi = function(daftar_kata, judul, subjudul, warna){
# Memecah daftar kata jadi daftar huruf
data_huruf = pecah_kata(daftar_kata)
# Menyimpan data panjang kata/jumlah kolom
colnum = ncol(data_huruf)
# List untuk menyimpan semua hasil
# agar nilainya bisa dikembalikan (return)
list_semua = list()
for (i in 1:colnum) {
# Menghitung persentase huruf pada posisi ke-i
# menggunakan persen_huruf_posisi()
letter_list = persen_huruf_posisi(data_huruf, i)
# Membuat plot grafik untuk posisi ke-i
# output langsung dalam file PNG
ggsave(
paste0(deparse(substitute(daftar_kata))
,"_posisi_",i,".png"),
plot_huruf(letter_list, paste0(
judul," pada Posisi ke-",i),
paste0("Dari daftar kata ",subjudul), warna),
width = 7,
height = 5,
dpi = 180
)
# Agar tampilan data pada tabel lebih mudah dibaca
letter_list[,2] = round(letter_list[,2],
digits = 2) %>%
format(nsmall = 2) %>%
paste0("%")
# Menampilkan data huruf di masing-masing posisi
# pada console
cat(paste0(judul," pada Posisi ke-",i,"\n"))
# Hanya menampilkan 5 huruf terbanyak
print(head(letter_list,5)) # List ga bisa pakai cat
cat("\n")
# Memasukkan data hasil pada list
list_semua[[i]] = letter_list
}
# Mengirimkan data pada list
return(list_semua)
}
Berikut ini hasil eksekusi fungsi tersebut di R console menggunakan data exclude_list melalui sintaks:
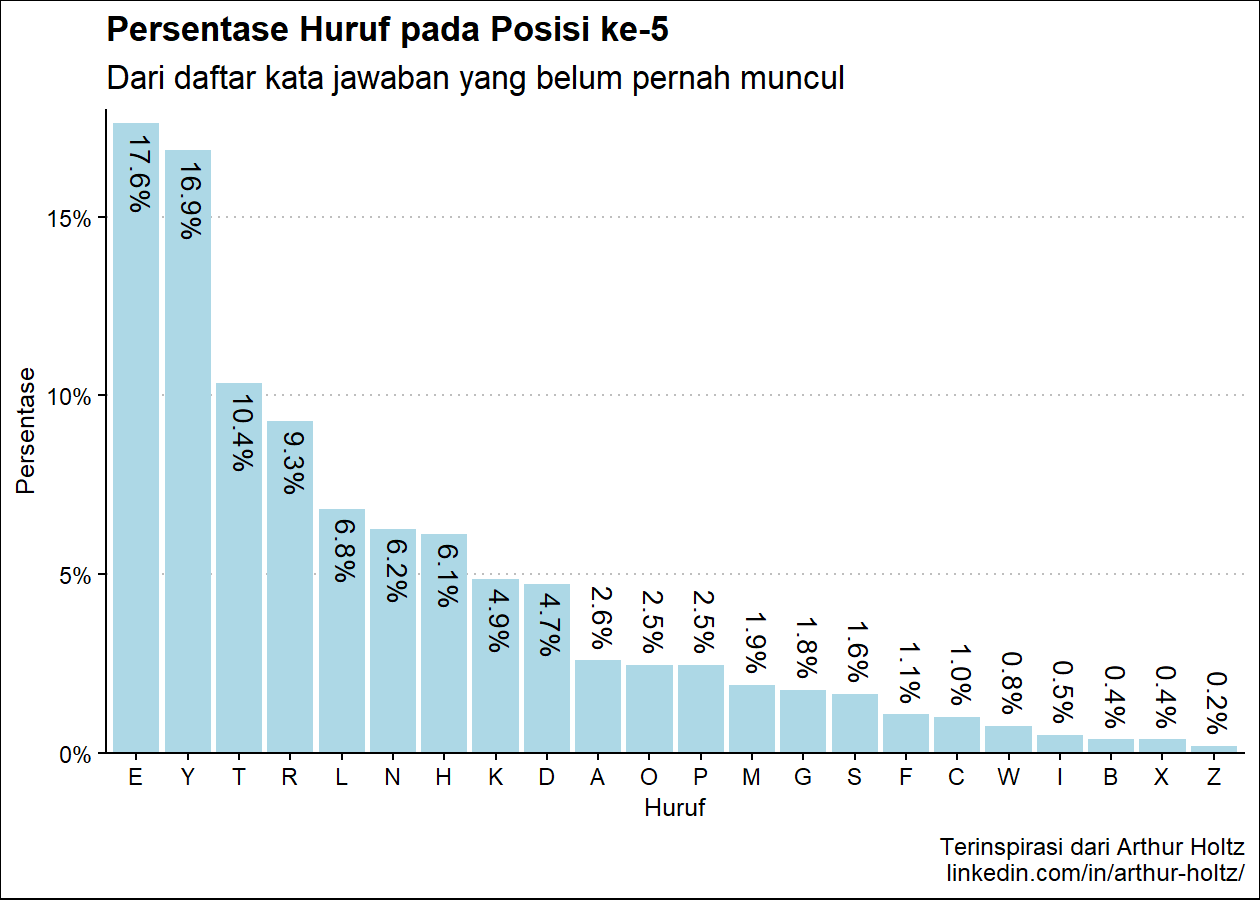
persen_plot_posisi(exclude_list, "Persentase Huruf", "jawaban yang belum pernah muncul", "lightblue")(Hasil berdasarkan data pada 16 Juni 2023)
Pada R console:
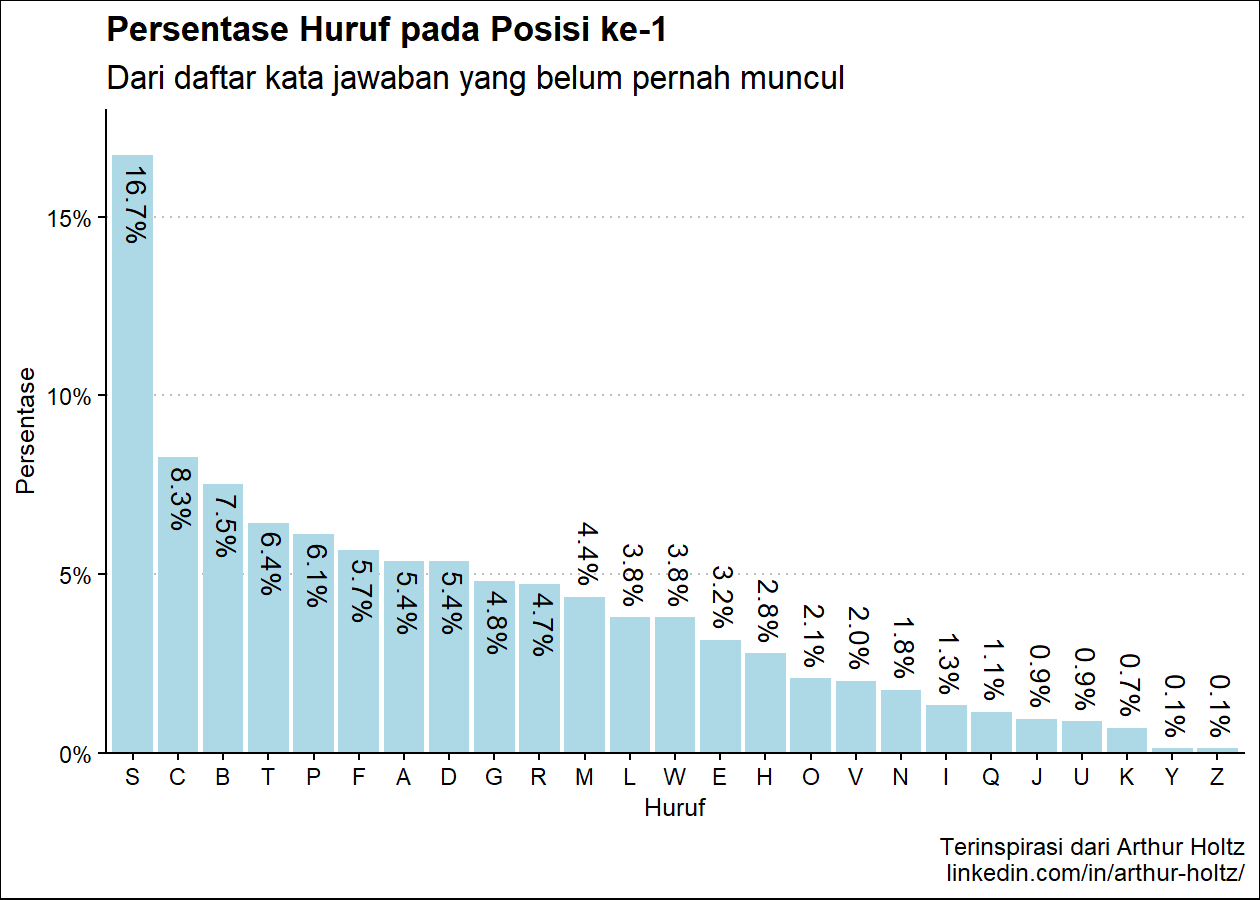

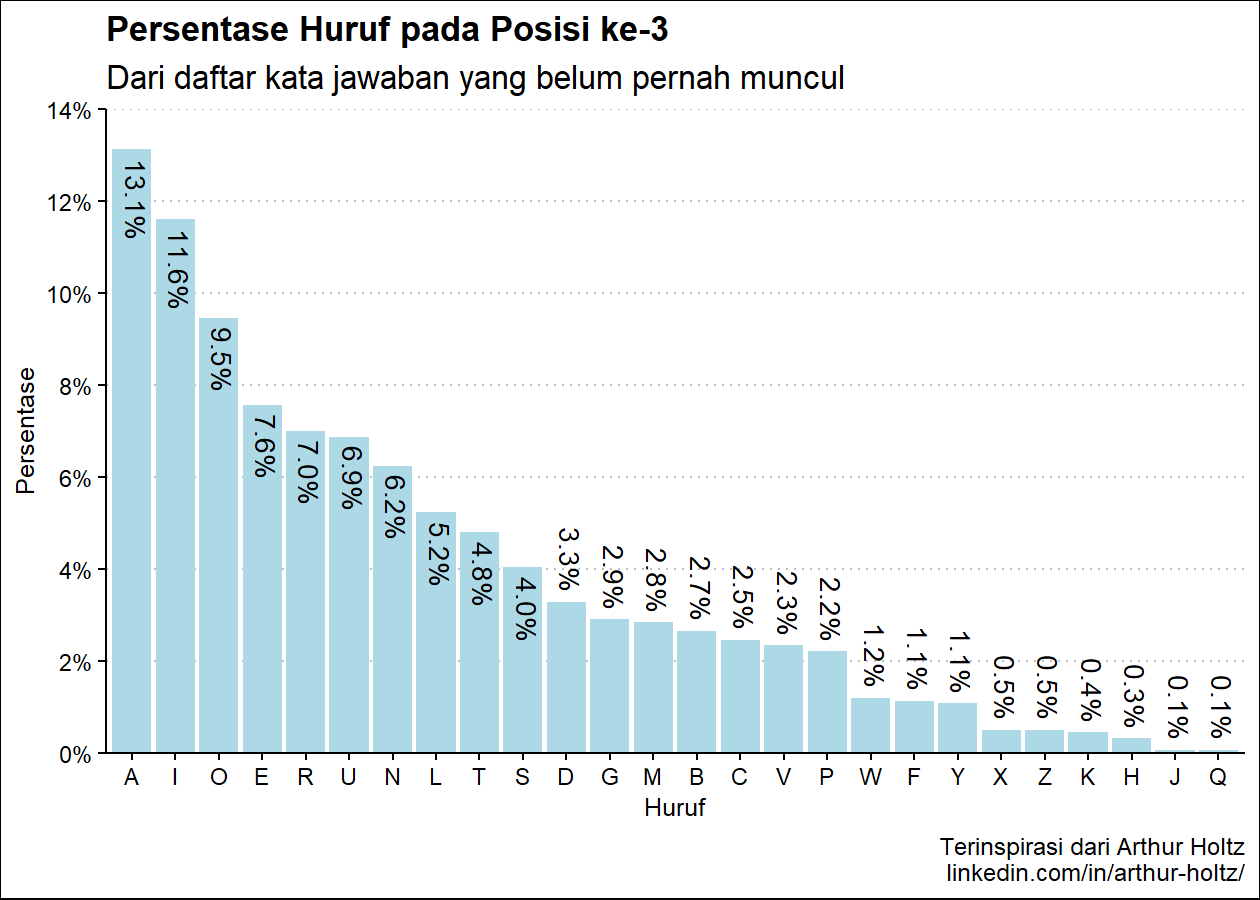
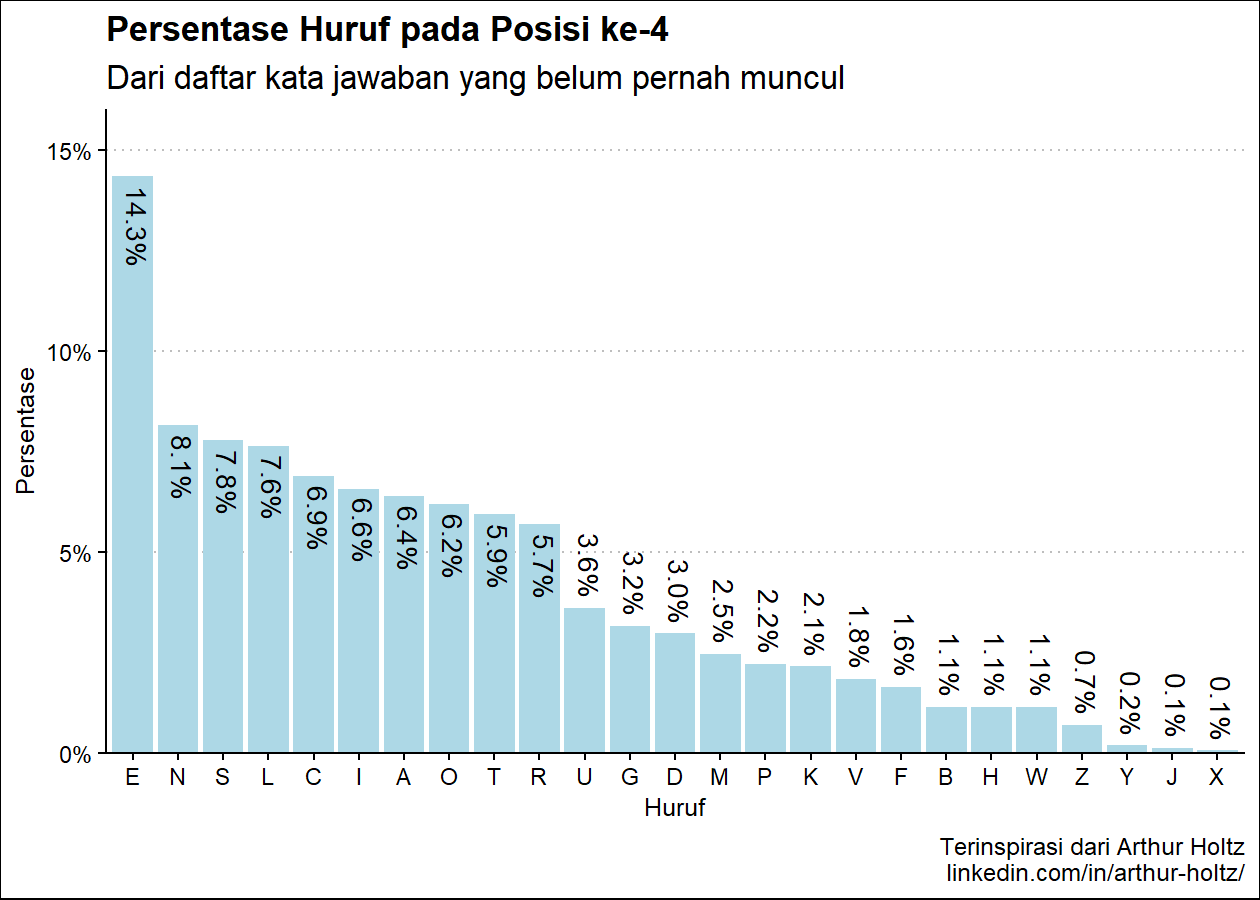
Hasil pada console:
Persentase Huruf pada Posisi ke-1
huruf persen
1 S 16.73%
2 C 8.27%
3 B 7.51%
4 T 6.44%
5 P 6.12%
Persentase Huruf pada Posisi ke-2
huruf persen
1 A 13.26%
2 R 11.36%
3 O 11.24%
4 E 11.05%
5 I 9.34%
Persentase Huruf pada Posisi ke-3
huruf persen
1 A 13.13%
2 I 11.62%
3 O 9.47%
4 E 7.58%
5 R 7.01%
Persentase Huruf pada Posisi ke-4
huruf persen
1 E 14.33%
2 N 8.14%
3 S 7.77%
4 L 7.64%
5 C 6.88%
Persentase Huruf pada Posisi ke-5
huruf persen
1 E 17.61%
2 Y 16.86%
3 T 10.35%
4 R 9.28%
5 L 6.82%(Daftar hasil masing-masing posisi sebenarnya lebih panjang, tapi dipotong agar tidak terlalu panjang dalam artikel ini.)
3 – Menemukan Kata dengan Potensi Probabilitas Tinggi
Ada dua cara yang perlu dilakukan untuk menemukan kata-kata yang akan dievaluasi nilai probabilitasnya:
- Menyaring (filter) data daftar kata dengan huruf-huruf terbanyak terlepas posisinya (hasil tahap 1). Bisa diasumsikan bahwa jika suatu kata terdiri dari huruf-huruf terbanyak maka setidaknya probabilitas kata tersebut mengandung huruf yang benar, meski posisinya keliru, akan tinggi.
- Menyaring data daftar kata pada masing-masing posisi dengan huruf terbanyak pada posisi tersebut (hasil tahap 2). Bisa diasumsikan bahwa ini akan menghasilkan kata dengan probabilitas tinggi memiliki huruf yang berada di posisi tepat.
Daftar kata mana yang akan disaring? Meski jawaban hanya ada di exclude_list, tapi variasi kata dan kombinasi huruf pada all_wordle_list bisa saja memberikan kata dengan probabilitas yang lebih tinggi di kedua cara. Pada analisis ini, kedua daftar kata akan disaring. Namun, data huruf terbanyak yang digunakan untuk menyaring tetap berasal dari hasil pengolahan data exclude_list di tahap 1 dan 2.
Cara Pertama: Disaring dengan Huruf Terbanyak
Huruf-huruf terbanyak dalam hal ini tentu maksudnya adalah huruf-huruf dengan persentase paling tinggi. Jika yang dicari adalah kata 5 huruf maka, kelima huruf tersebut harus merupakan 5 huruf terbanyak pada data, terlepas dari urutannya.
Bagaimana jika tidak ada kata yang terdiri 5 huruf tersebut dalam data? Misalnya, jika huruf terbanyak adalah A, N, G, Y, dan R, tapi ternyata hanya ada kata dengan huruf A, N, G, dan R, apa yang perlu dilakukan? Solusi saya di sini adalah mengambil huruf terbanyak selanjutnya (urutan ke-6). Jika masih tidak ada, ambil urutan selanjutnya lagi. Meski bisa jadi tidak akurat, solusi ini cukup praktikal.
Karenanya, cara ini adalah pendekatan saja. Secara intuitif memang seharusnya kata yang dibentuk dari huruf terbanyak ke-1, 2, 3, 4, dan 6 akan lebih membantu menemukan huruf yang ada pada jawaban daripada huruf terbanyak ke-1, 5, 7, 8, dan 9 misalnya.
Algoritma pencarian kata-kata ini dibuatkan ke dalam fungsi tebakan_cara1(). Fungsi ini memiliki input parameter berupa data sumber pencarian kata (daftar_kata_sumber) yang akan disaring menggunakan huruf-huruf terbanyak dari data daftar kata jawaban (daftar_kata). Kedua parameter bisa saja menggunakan data yang sama.
Dalam fungsi ini, huruf terbanyak dihitung menggunakan fungsi persen_huruf() pada daftar_kata. Kemudian, huruf-huruf dari hasil fungsi tersebut dijadikan filter pada data daftar_kata_sumber satu per satu mulai dari huruf terbanyak sampai data tersebut sudah di-filter menggunakan 5 huruf yang berbeda. Jika setelah di-filter oleh suatu huruf hasilnya adalah NULL (tidak ada kata yang mengandung huruf tersebut pada data), huruf tersebut dilewat dan huruf lain akan menggantikannya agar kata tepat di-filter oleh 5 huruf.
Fungsi ini akan menampilkan 5 huruf yang digunakan untuk mem-filter data dan menghasilkan output berupa data kata-kata yang berpotensi probabilitas tinggi.
# Fungsi menemukan kata terbaik Cara 1 (huruf bebas posisi)
tebakan_cara1 = function(daftar_kata, daftar_kata_sumber){
# Membuat tabel persentase huruf
data_huruf = persen_huruf(daftar_kata)
# Mengambil daftar huruf dari persentase huruf untuk filter
letter_filter = data_huruf[,1]
# Membuat variabel untuk perubahan daftar kata yang difilter
list_baru = daftar_kata_sumber
# Variabel pembantu untuk menskip huruf
j = 0
# Menghitung panjang kata
# dengan ini, fungsi bisa digunakan untuk kata selain 5 huruf
# Kata yang diambil hanya kata teratas saja yang dapat
# mewakili kata-kata lain pada daftar
huruf_per_kata = str_length(daftar_kata[1,1])
# Membuat data huruf dengan persentase tertinggi
# untuk ditampilkan
data_persen_huruf = data.frame(huruf = character(),
persen = double())
# Filter daftar kata dengan masing-masing huruf
# Setelah difilter dengan satu huruf, list_baru akan diupdate
# lalu difilter lagi dengan huruf lain
for(i in unlist(letter_filter)){
# Hasil filter langsung disimpan ke variabel baru
list_baru0 = filter(list_baru,
grepl(i, unlist(list_baru[1])))
# Cek hasil filter di list_baru0:
# jika tidak kosong (ada kata-kata yang cocok)
# update list_baru, dan tambah j
# Jika tidak, loop dilanjutkan tanpa update list_baru
# Jika j = jumlah huruf per kata, hentikan loop
if((nrow(list_baru0)!= 0)&&(j!= huruf_per_kata)){
j = j+1
list_baru = list_baru0
# Menyimpan data tiap huruf filter dan persentasenya
# data persen langsung diformat dalam persentase
data_persen_huruf[j,] = c(i,paste0(format(round(
data_huruf[which(data_huruf[1] == i),2],
digits = 2),
nsmall = 2),"%"))
if (j == huruf_per_kata){
break
}
}
}
# Menampilkan huruf-huruf terbanyak
# yang bisa membentuk kata dan persentasenya
cat("Huruf-huruf terbanyak yang tersedia\n")
print(data_persen_huruf)
# Menyeragamkan nama kolom
names(list_baru)[1] = "kata"
# Menampilkan Judul Hasil
cat("\nDaftar Kata Hasil\n")
# Mengirimkan data output
return(list_baru)
}
Berikut ini hasil eksekusi fungsi tersebut di R console menggunakan data exclude_list sebagai sumber data penghitungan huruf dan all_wordle_list sebagai sumber data pencarian kata:
(Hasil berdasarkan data pada 16 Juni 2023)
Sintaks:
tebakan_cara1(exclude_list, all_wordle_list)Hasil:
Huruf-huruf terbanyak yang tersedia
huruf persen
1 E 45.14%
2 A 38.13%
3 R 35.10%
4 L 28.35%
5 I 28.28%
Daftar Kata Hasil
kata
1 ARIEL
2 RAILEMenggunakan data exclude_list sebagai sumber data penghitungan huruf pencarian kata memberikan hasil sebagai berikut:
Sintaks:
tebakan_cara1(exclude_list, exclude_list)Hasil:
Huruf-huruf terbanyak yang tersedia
huruf persen
1 E 45.14%
2 A 38.13%
3 R 35.10%
4 L 28.35%
5 T 27.71%
Daftar Kata Hasil
kata
1 LATER
2 ALERTCara Kedua: Disaring dengan Huruf Terbanyak di Tiap Posisi
Berikutnya adalah melakukan pemisahan kata menjadi huruf, mencari huruf terbanyak per posisi, dan langsung menyaring daftar kata pada tiap posisi huruf sesuai dengan huruf terbanyak per posisi.
Di sini, definisi huruf terbanyak makin sulit didefinisikan. Kita tidak bisa menggunakan definisi yang sama dengan cara 1 karena huruf terbanyak pada dua posisi atau lebih bisa saja huruf yang sama. Ada dua pendekatan yang bisa digunakan:
Disaring Berdasarkan Urutan Persentase Huruf Terbanyak
Pada metode ini, sebuah data kata disaring berdasarkan huruf pada posisi tertentu dengan urutan penyaringan berdasarkan jumlah persentase paling tinggi dari suatu huruf pada posisi tertentu. Misalnya, kita memiliki data huruf paling banyak di tiap posisi adalah sebagai berikut:
| Huruf | Persentase | Posisi |
| A | 15% | 1 |
| A | 16% | 2 |
| L | 17% | 3 |
| T | 10% | 4 |
| E | 16,5% | 5 |
Jika diurutkan, maka akan menjadi:
| Huruf | Persen | Posisi |
| L | 17% | 3 |
| E | 16,5% | 5 |
| A | 16% | 2 |
| A | 15% | 1 |
| T | 10% | 4 |
Berdasarkan data di atas, daftar kata pertama-tama disaring dengan huruf L pada posisi huruf ke-3, huruf E pada posisi ke-5, dan seterusnya.
Jika setelah disaring dengan suatu huruf pada posisi tertentu menghasilkan daftar kosong (tidak ada kata dengan kombinasi huruf yang sudah disaring), maka huruf diganti dengan urutan kedua terbanyak pada posisi tersebut.
Untuk menjamin bahwa urutan penyaringan tetap berdasarkan persentase tertinggi, persentase huruf tersebut diurutkan lagi dengan persentase huruf pada posisi yang belum disaring. Kemudian penyaringan daftar kata dilanjutkan seperti biasa.
Secara intuitif, pendekatan ini dapat menjamin bahwa kata yang digunakan memiliki huruf dengan persentase kemunculan tertinggi di tiap posisinya.
Metode ini saya tuliskan sebagai fungsi tebakan_cara2A().
# Fungsi menemukan kata terbaik Cara 2A (terikat posisi)
# Pendekatan dengan melakukan penyaringan berurut
tebakan_cara2A = function(daftar_kata, daftar_kata_sumber){
# Membuat daftar kata yang dipisah per posisi
# baik untuk sumber data huruf
# maupun sumber kata yang akan disaring
data_huruf = pecah_kata(daftar_kata)
data_kata = pecah_kata(daftar_kata_sumber)
# Menyimpan data jumlah huruf per kata
colnum = ncol(data_huruf)
# Membuat data huruf dengan persentase tertinggi
# di tiap posisi
max_per_pos = data.frame(huruf = character(),
persen = double(),
pos = integer())
# Mulai loop untuk membuat daftar
# persentase huruf untuk semua posisi
# dan mengisi data max_per_pos
for (i in 1:colnum) {
# Menghitung persentase huruf pada posisi ke-i
letter_list = persen_huruf_posisi(data_huruf, i)
# Memasukkan hasil dan persentase ke masing-masing
# tabel data per posisi
data_huruf_pos = paste0("pos_",i)
assign(data_huruf_pos, letter_list)
# Memasukkan data persentase tertinggi
# ke data max_per_pos
max_per_pos[i,] =
c(eval(sym(paste0("pos_",i)))[1,1],
eval(sym(paste0("pos_",i)))[1,2],
i)
}
# Mengurutkan data posisi dengan persentase tertinggi
max_per_pos = arrange(max_per_pos,desc(persen)) %>%
data.frame()
# Memisahkan data untuk tampilan
# dengan data untuk diproses
max_per_pos_p = max_per_pos
# Memberikan format persen
# pada data tampilan
max_per_pos_p[,2] =
as.numeric(max_per_pos_p[,2]) %>%
round(digits = 2) %>%
format(nsmall = 2) %>%
paste0("%")
# Mengecek isi max_per_pos
# (versi tampilan) yang sudah diurut
print(max_per_pos_p)
# Menyiapkan variabel-variabel pembantu untuk
# loop penyaringan:
# Menyalin data sumber kata ke data baru
list_baru = data_kata
j = 1 #jumlah penyaringan berhasil
k = 1 #indeks urutan persentase huruf di posisi
# Mulai loop untuk penyaringan
# Kata akan disaring terus hingga
# semua posisi sudah disaring
# dan menghasilkan minimal 1 kata (tidak kosong)
while(j <= nrow(max_per_pos)){
# Indeks posisi huruf dari kata yang akan disaring
# Perlu diconvert ke numeric untuk memastikan
# angka bisa jadi indeks kolom
idx = as.numeric(max_per_pos[j,3])
# Tabel daftar persentase huruf pada posisi
# yang sedang disaring
# diperlukan jika penyaringan dengan huruf teratas
# menghasilkan data kosong
tabel_eval = eval(sym(paste0("pos_",idx)))
# Mengambil huruf untuk penyaringan
huruf_filter = unlist(max_per_pos[j,1])
# Menyaring kata pada list_baru dengan
# huruf huruf_filter pada posisi idx
hasil_filter_huruf = filter(list_baru,
list_baru[,idx] == huruf_filter)
# Jika menghasillkan daftar kata kosong ...
if(nrow(hasil_filter_huruf) == 0){
# Mengisi k dengan indeks huruf
# yang sedang disaring pada tabel_eval
# sesuai posisi
k = unlist(which(tabel_eval[1] == huruf_filter))
# Jika huruf pengganti di suatu posisi habis
# hentikan loop, berikan peringatan
if(k >= nrow(tabel_eval)){
print("Kata tidak tersedia")
break
}
# Mengubah isi max_per_pos
# dengan huruf terbanyak selanjutnya
# pada posisi tersebut
max_per_pos[j,] = c(
tabel_eval[k+1,1],
tabel_eval[k+1,2], idx)
# Mengurutkan data kembali sesuai persentase
max_per_pos = arrange(max_per_pos,desc(persen))
# Lanjutkan loop
next
}else{
# Jika penyaringan menghasilkan
# daftar kata baru minimal 1 kata
# update list_baru dengan
# data hasil penyaringan
list_baru = hasil_filter_huruf
# Update jumlah penyaringan berhasil
j = j+1
}
}
# Menggabungkan data dari 5 kolom huruf
# ke 1 kolom kata
merge_str = unlist(list_baru[1])
for(j in 2:colnum){
merge_str = paste(merge_str, unlist(list_baru[j]))
}
# Membersihkan hasil merge
# dari separator dan memberi nama kolom
merge_str = data.frame(
str_replace_all(
unlist(merge_str), " ", "")) %>%
select(hasil = 1)
# Update data hasil dengan kata yang sudah digabung
list_baru = data.frame(merge_str)
# Menyeragamkan nama kolom
names(list_baru)[1] = "kata"
# Menampilkan Judul Hasil
cat("\nDaftar Kata Hasil\n")
# Mengirimkan data output
return(list_baru)
}Berikut ini hasil eksekusi fungsi tersebut di R console menggunakan data exclude_list sebagai sumber data penghitungan huruf dan all_wordle_list sebagai sumber data pencarian kata:
(Hasil berdasarkan data pada 16 Juni 2023)
Sintaks:
tebakan_cara2A(exclude_list, all_wordle_list)Hasil:
huruf persen pos
1 E 17.61% 5
2 S 16.73% 1
3 E 14.33% 4
4 A 13.26% 2
5 A 13.13% 3
Daftar Kata Hasil
kata
1 SAREE
2 SAYEEMenggunakan data exclude_list sebagai sumber data penghitungan huruf pencarian kata memberikan hasil sebagai berikut:
Sintaks:
tebakan_cara2A(exclude_list, exclude_list)Hasil:
huruf persen pos
1 E 17.61% 5
2 S 16.73% 1
3 E 14.33% 4
4 A 13.26% 2
5 A 13.13% 3
Daftar Kata Hasil
kata
1 SPREE
2 SCREEMenggunakan Persentil di Tiap Persentase Huruf Per Posisi
Metode ini pada dasarnya cara saya untuk menentukan huruf-huruf terbanyak di tiap posisi dengan logika yang terlihat valid dan tidak acak.
Pada metode ini, saya menggunakan fungsi quantile() pada daftar persentase huruf di tiap posisi untuk menentukan persentase minimal huruf terbanyak dengan menentukan persentil dari distribusi normal. Persentil menunjukkan jumlah populasi pada nilai probabilitas tertentu.
Singkatnya, kita bisa menentukan nilai persentil ke-x, menghitung probabilitas minimal pada persentil tersebut, dan memilih huruf-huruf yang nilai persentasenya di atas probabilitas minimal sebagai huruf terbanyak.
Terdapat aturan 68-95-99.7 yang dapat membantu menentukan nilai persentil yang digunakan. Perlu diingat bahwa persentil tinggi dapat menghasilkan nilai probabilitas minimal yang tinggi sehingga huruf-huruf yang masuk syarat semakin sedikit. Dan sebaliknya untuk nilai persentil kecil.
Kita tidak dapat mengetahui nilai persentil yang tepat untuk hasil huruf-huruf terbanyak yang tepat. Jadi, dalam fungsi yang dibuat, terdapat parameter persentil untuk mencoba-coba nilai persentil agar tidak menghasilkan nilai kosong tapi juga tidak menghasilkan terlalu banyak kata tebakan.
Fungsi ini memerlukan input berupa daftar kata yang akan dicari huruf-huruf terbanyaknya per posisi (daftar_kata), daftar kata yang akan disaring (daftar_kata_sumber), serta nilai persentil yang diuji.
Pertama-tama kita menerapkan fungsi pecah_kata() pada daftar_kata dan daftar_kata_sumber. Yang pertama untuk dicarikan huruf terbanyak per posisi, sedangkan yang kedua agar bisa disaring per posisi.
Untuk menentukan persentase huruf di tiap posisi, fungsi persen_huruf_posisi() digunakan kembali. Pada fungsi tersebut juga terdapat parameter untuk memilih kolom mana yang akan dihitung posisi terbanyaknya.
Setelah menghitung persentase tiap huruf pada suatu posisi, diperlukan definisi untuk memilih huruf terbanyak. Di sini definisi persentil digunakan. Daftar huruf terbanyak tersebut langsung digunakan untuk menyaring daftar_kata_sumber yang sudah dipecah menjadi 5 kolom pada posisi huruf tertentu sehingga menghasilkan daftar kata baru.
Proses ini dimuat dalam sebuah loop yang akan memproses masing-masing kolom atau posisi huruf dari posisi pertama hingga akhir. Pada tiap iterasi, daftar kata hasil penyaringan (list_baru) akan disaring untuk memperkecil daftar kata dan fokus pada sedikit kata saja.
Setelah daftar kata jawaban dihasilkan, kolom-kolom huruf digabungkan kembali menjadi kata.
Berikut ini sintaks fungsinya:
# Fungsi menemukan kata terbaik Cara 2B (terikat posisi)
# Pendekatan dengan menggunakan persentil
tebakan_cara2B = function(daftar_kata,
daftar_kata_sumber,
persentil = 0.954){
# Memanggil fungsi memecah kata untuk
# daftar kata yang dicari huruf terbanyaknya
# dan daftar kata yang akan disaring
data_huruf = pecah_kata(daftar_kata)
data_huruf_sumber = pecah_kata(daftar_kata_sumber)
# Menghitung jumlah kolom/huruf
colnum = ncol(data_huruf)
# Variabel untuk menampung daftar kata hasil filter
list_baru = data_huruf_sumber
# Membuat data huruf dengan persentase tertinggi
# untuk ditampilkan
data_persen_huruf = data.frame(huruf = character(),
persen = double())
# Loop untuk mencari huruf terbanyak
# di masing-masing posisi
# Huruf tersebut langsung digunakan untuk
# filter pada list_baru
# Jumlah loop sesuai jumlah kolom/huruf per kata
for (i in 1:colnum) {
# Menghitung persentase huruf pada posisi ke-i
letter_list = persen_huruf_posisi(data_huruf, i)
# Persyaratan huruf terbanyak menggunakan persentil
# nilainya tergantung parameter persentil
# Nilai persen huruf yang sesuai persentil dihitung
kuantil_x = quantile(unlist(letter_list[2]),
probs = persentil)
# Kemudian, huruf dengan nilai persen lebih besar dari
# persentil disaring dan disimpan
letter_filter =
letter_list[which(letter_list[2] > kuantil_x),1:2]
# Membuat huruf-huruf filter dalam satu baris string
# hanya untuk ditampilkan dalam tabel data
merge_huruf = letter_filter[1,1]
if(nrow(letter_filter[1])>1){
for(x in 2:nrow(letter_filter[1])){
merge_huruf = paste0(merge_huruf, ", " ,
letter_filter[x,1])
}
}
# Memasukkan data huruf filter dan persentasenya
data_persen_huruf[i,] = c(merge_huruf,
paste0(format(round(
kuantil_x,
digits = 2),
nsmall = 2)
,"%"))
# Daftar kata disaring berdasarkan huruf-huruf filter
list_baru = filter(list_baru,
unlist(list_baru[i])
%in% unlist(letter_filter[1]))
}
# Menggabungkan data dari 5 kolom huruf
# ke 1 kolom kata
merge_str = unlist(list_baru[1])
for(j in 2:colnum){
merge_str = paste(merge_str, unlist(list_baru[j]))
}
# Membersihkan hasil merge
# dari separator dan memberi nama kolom
merge_str =
data.frame(str_replace_all(
unlist(merge_str), " ", "")) %>%
select(hasil = 1)
# Update data hasil dengan kata yang sudah digabung
list_baru = data.frame(merge_str)
# Menampilkan data huruf-huruf filter dan persentasenya
cat(paste0("Huruf-huruf Filter di atas Persentil ke-",
persentil*100, "%\n"))
print(data_persen_huruf)
# Menyeragamkan nama kolom
names(list_baru)[1] = "kata"
# Menampilkan Judul Hasil
cat("\nDaftar Kata Hasil\n")
# Mengirimkan data output
return(list_baru)
}
Berikut ini hasil eksekusi fungsi tersebut di R console menggunakan data exclude_list sebagai sumber data penghitungan huruf dan all_wordle_list sebagai sumber data pencarian kata dan nilai persentil 0.954:
(Hasil berdasarkan data pada 16 Juni 2023)
Sintaks:
tebakan_cara2B(exclude_list, all_wordle_list, 0.954)Hasil:
Huruf-huruf Filter di atas Persentil ke-95.4%
huruf persen
1 S, C 8.19%
2 A, R 11.35%
3 A, I 11.29%
4 E, N 8.10%
5 E 16.88%
Daftar Kata Hasil
kata
1 CRINE
2 SAINE
3 CRANEMenggunakan data exclude_list sebagai sumber data penghitungan huruf pencarian kata memberikan hasil sebagai berikut:
Sintaks:
tebakan_cara2B(exclude_list, exclude_list, 0.954)Hasil:
Huruf-huruf Filter di atas Persentil ke-95.4%
huruf persen
1 S, C 8.19%
2 A, R 11.35%
3 A, I 11.29%
4 E, N 8.10%
5 E 16.88%
Daftar Kata Hasil
kata
1 CRANESetelah dicoba, persentil 99,7% tidak menghasilkan kata apapun sedangkan persentil 68,2% menghasilkan terlalu banyak kata. Persentil 95% (tepatnya 95,4%) menghasilkan beberapa kata tebakan yang cukup untuk dihitung nilai probabilitasnya nanti. Karenanya dalam sintaks deklarasi fungsi, saya tuliskan paramter persentil dengan nilai default 0.954.
4 – Menghitung Nilai Probabilitas Masing-Masing Kata Tebakan
Untuk memvalidasi dan mengukur kualitas kata tebakan, nilai probabilitas kata tebakan akan dihitung. Seperti sudah disebutkan sebelumnya, kita bisa menghitung probabilitas huruf-huruf dalam suatu kata terdapat dalam kata jawaban baik salah satu, dua, hingga kelima hurufnya. Itu berlaku untuk probabilitas huruf benar di posisi yang bebas maupun tepat.
Pada dasarnya, penghitungan probabilitas suatu kata ini dilakukan dengan menghitung jumlah kata dalam daftar kata yang mengandung variasi kombinasi huruf-huruf pembentuk kata. Misalnya, pada kata “ACRUE”, kita bisa menghitung berapa kata dalam daftar exclude_list yang mengandung huruf “A”, “C”, “AC”, “ACR”, dst. Ini akan lebih mudah dipahami jika membayangkan tiap huruf sebagai himpunan-himpunan yang beririsan dalam semesta daftar kata. Karenanya, saya akan membuat visualisasi ini saat validasi.
Tantangan selanjutnya adalah, apa yang perlu dilakukan pada hasil penghitungan yang rumit ini agar kita menemukan kata terbaik? Setiap kata yang dihasilkan dari tahap 3 analisis ini diasumsikan akan menghasilkan nilai probabilitas yang tinggi. Namun, bagaimana menentukan yang terbaik dari kata-kata tersebut?
Kita bisa menentukannya berdasarkan kemungkinan salah satu huruf terdapat pada jawaban karena kemungkinannya pasti besar. Atau, bisa juga berdasarkan kemungkinan 3 dari 5 huruf terdapat pada jawaban karena informasi yang didapatkan akan sangat membantu dan nilai probabilitasnya seharusnya masih cukup besar. Atau, kita bisa mengacu pada nilai probabilitas huruf bebas terlebih dahulu, baru membandingkan nilai huruf pada posisi tepat-nya.
Namun, agar seluruh nilai probablitas terpakai, saya akan menjumlahkan seluruh nilai probabilitas (kemungkinan satu hingga 5 huruf benar baik bebas posisi maupun tepat) lalu mengurutkan dari yang terbesar. Setelah diurut berdasarkan jumlah nilai, saya juga akan mengurutkan berdasarkan nilai satu huruf bebas posisi, satu huruf tepat posisi, 3 huruf bebas posisi, dan 3 huruf tepat posisi meski sepertinya akan berpengaruh kecil pada urutan.
Nilai probabilitas ini juga digunakan untuk melihat cara tebakan kata yang lebih baik dari pendekatan yang kita lakukan di analisis tahap 1 dan 2.
Menyaring Kata dengan 2 Huruf yang Sama
Saat percobaan penghitungan probabilitas, saya menemukan bahwa kata dengan 2 huruf yang sama, misalnya “SAREE”, memberikan nilai probabilitas huruf bebas yang janggal. Pada kata tersebut, nilai probabilitas 5 huruf benar di posisi bebas akan sama dengan probabilitas 4 huruf benar. Untuk mencegah hal ini mempengaruhi nilai akhir, saya membuat fungsi huruf_unik() yang akan dipergunakan saat membuat visualisasi diagram venn dan menghitung nilai akhir.
Fungsi ini menghilangkan huruf ganda dalam suatu kata input sehingga penghitungan dan visualisasi lebih akurat.
# Fungsi untuk menghilangkan huruf yang sama
# dalam satu kata
huruf_unik = function(kata_eval){
# Memastikan kata yang dievaluasi merupakan data frame
# agar bisa diolah lebih lanjut
if(!is.data.frame(kata_eval)){
kata_eval = data.frame(kata = c(kata_eval))
}
# Memecah kata evaluasi menjadi huruf per posisi
huruf_kata = pecah_kata(kata_eval)
# Variabel menyimpan kata hasil
kata_hasil = ""
for (i in 1:ncol(huruf_kata)) {
# Mengecek apakah suatu huruf
# pernah ada di kata tersebut atau belum
cek_ada = grepl(huruf_kata[i],kata_hasil)
# Jika belum ada, tambahkan huruf
# pada kata_hasil
if(!cek_ada){
kata_hasil = paste0(kata_hasil,huruf_kata[i])
}
}
# Mengirimkan kata hasil
return(kata_hasil)
}
Contoh penggunaannya adalah sebagai berikut:
Sintaks: huruf_unik(“SAREE”)
Output: “SARE”
Membuat Visualiasasi Diagram Venn
Untuk lebih memahami proses penghitungan probabilitas, saya membuat fungsi untuk menampilkan diagram venn dari himpunan kata yang mengandung huruf-huruf dalam kata yang dievaluasi. Fungsi ini menggunakan library venn yang dapat membuat diagram venn hingga 7 himpunan. Kelemahannya adalah tidak bisa menampilkan nilai persentase dalam diagramnya, tapi saat ini itu tidak diperlukan. Kita menggunakannya hanya untuk visualisasi saja.
Pada fungsi ini, daftar kata disaring masing-masing oleh huruf-huruf pembentuk kata yang akan dievaluasi. Metode penyaringan dapat dilakukan dengan mode bebas atau tepat posisi. Pemilihan mode ini menjadi parameter mode dalam input fungsi. Pilihannya adalah “bebas” atau “posisi”.
Sebagai contoh, jika kata yang akan dievaluasi adalah “CRANE” dalam mode “posisi”, maka diagram venn yang ditampilkan adalah himpunan daftar kata yang memiliki “C” di posisi pertama, himpunan “R” di posisi ke-2, dst. hingga “E” di posisi ke-5. Diagram akan menampilkan kelima himpunan beserta irisannya dan menampilkan jumlah kata yang ada di masing-masing irisan.
Perlu dicatat bahwa dalam fungsi ini saya menggunakan perintah parse() yang dapat memperlakukan suatu teks string sebagai sintaks kode dan eval() yang dapat mengeksekusi sintaks tersebut. Ini diperlukan karena sintaks dibentuk lewat string yang ditambahkan lewat looping. Untuk lebih jelasnya dapat dilihat langsung pada fungsi gambar_venn() berikut:
# Fungsi untuk menggambar diagram venn dari kata
# "bebas" -> huruf benar terlepas posisinya
# "posisi" -> huruf benar di posisi yang benar
gambar_venn = function(kata_eval, asal_data, mode = "bebas"){
# Memastikan kata yang dievaluasi merupakan data frame
# agar bisa diolah lebih lanjut
if(!is.data.frame(kata_eval)){
kata_eval = data.frame(kata = c(kata_eval))
}
# Menyiapkan asal_data sesuai mode
# Pada mode posisi, asal_data perlu dipecah
# agar bisa di-filter sesuai posisi.
# Pada mode bebas, tidak perlu dipecah
if(mode == "posisi"){
# Memecah data kata sumber menjadi huruf per posisi
daftar_kata = pecah_kata(asal_data)
# Menyimpan data jumlah huruf per kata
colnum = ncol(daftar_kata)
}else if(mode == "bebas"){
# Agar penamaan variable tetap sama
daftar_kata = asal_data
# Memastikan tidak ada huruf yang sama
kata_eval = huruf_unik(kata_eval)
# Menyimpan data jumlah huruf per kata
colnum = str_length(kata_eval)
}
# Memecah kata evaluasi menjadi huruf per posisi
huruf_kata = pecah_kata(kata_eval)
# Pengecekan jika huruf lebih dari 7
if(colnum > 7){
return("Jumlah huruf terlalu banyak.")
}
# Untuk mengecek apakah jumlah huruf kata_eval
# sama dengan huruf-huruf di daftar kata sumber
if(str_length(asal_data[1,1])!= colnum){
# Pada mode bebas, beri peringatan jika
# huruf unik jumlahnya berbeda
if(mode == "bebas"){
cat("\nPeringatan dari gambar_venn():")
cat("\nJumlah huruf unik beda dengan daftar\n")
}else{
return("Jumlah huruf input kata
beda dengan daftar kata.")
}
}
# Menyiapkan string yang akan dieksekusi
# untuk membuat list sebagai input pada venn()
fun_str = "list("
# Memulai loop untuk penyaringan di tiap posisi huruf
# Jumlah loop sesuai jumlah huruf dalam satu kata
for (i in 1:colnum) {
# Melakukan filter pada daftar kata tergantung mode
# Data yang disaring selalu data sumber awal yang sama,
# bukan hasil penyaringan sebelumnya
if(mode == "bebas"){
# Pada mode bebas, penyaringan menggunakan grepl
# untuk mencari kata yang mengandung huruf tertentu
hasil_filter_huruf =
filter(daftar_kata,
grepl(huruf_kata[1,i],
unlist(daftar_kata[1])))
# Menyeragamkan variable di kedua mode
final_list = unlist(hasil_filter_huruf)
# Prefiks untuk pelabelan pada diagram
prefiks = "_bebas"
}else if (mode == "posisi"){
# Pada mode posisi, penyaringan dilakukan
# dengan filter kolom
hasil_filter_huruf = filter(daftar_kata,
unlist(daftar_kata[,i]) ==
huruf_kata[1,i])
# Merge 5 kolom jadi satu
final_list = unlist(hasil_filter_huruf[,1])
for(j in 2:colnum){
final_list = paste(final_list,
unlist(hasil_filter_huruf[,j]))
}
# Prefiks untuk pelabelan pada diagram
prefiks = paste0("_pos_",i)
}
# Update daftar huruf untuk memperjelas
# pelabelan pada diagram venn
huruf_kata[1,i] = paste0(huruf_kata[1,i],
prefiks)
# Memasukkan hasil merge sebagai
# data himpunan hasil penyaringan ke-i
result_fil = paste0("hasil_",i)
assign(result_fil, final_list)
# Update teks dengan variabel himpunan
fun_str = ifelse(i == colnum,
paste0(fun_str, result_fil, ")"),
paste0(fun_str, result_fil," , "))
}
# Mengeksekusi perintah teks untuk membuat list
venal_table = eval(parse(text = fun_str))
# Memasukkan list dalam venn()
venn(venal_table, snames = unlist(huruf_kata),
ilab = TRUE, ilcs = 0.6, zcol = "style",
ggplot = TRUE, box = FALSE)
# Fungsi tidak menghasilkan keluaran
# selain diagram venn
}
Berikut ini contoh eksekusi fungsi dengan sintaks:
gambar_venn("BLAST", exclude_list, "posisi")(Hasil berdasarkan data pada 16 Juni 2023)
Hasil:
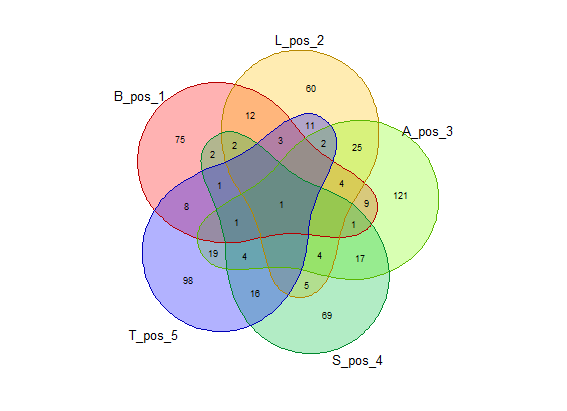
Dari hasil di atas kita bisa saja menghitung jumlah masing-masing kata di tiap irisan dan menghitung probabilitasnya. Tapi R memungkinkan kita untuk menghitungnya secara otomatis.
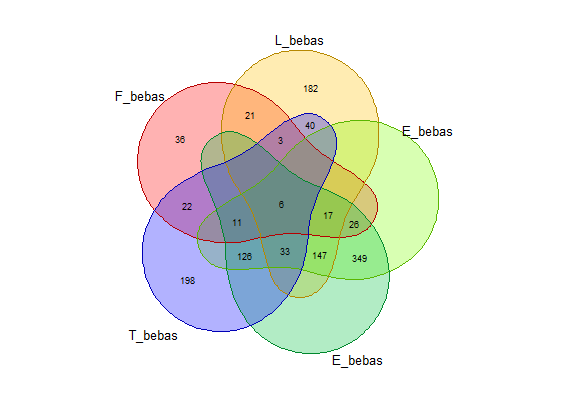
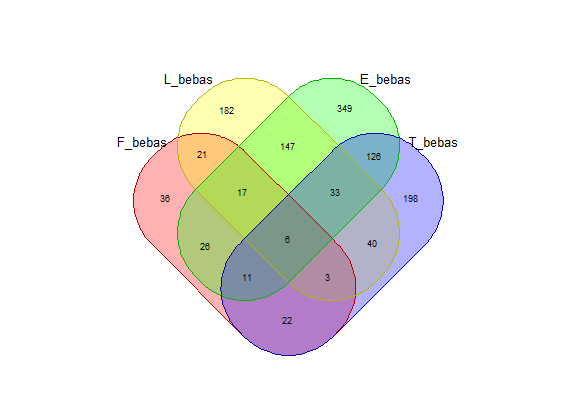
Fungsi di atas telah menggunakan fungsi huruf_unik() yang mencegah diagram venn yang agak aneh saat ada huruf ganda dalam suatu kata pada mode “bebas”. Berikut ini contoh perbandingan diagram venn untuk kata “FLEET” jika huruf_unik() digunakan (kanan) dan tidak (kiri). Adanya 2 himpunan E tidak masuk akal pada konteks mode “bebas” khususnya jika kita ingin melakukan visualisasi untuk melihat jumlah kata yang beririsan. Pada mode “posisi” hal ini tidak menjadi persoalan karena huruf yang sama di posisi berbeda akan diwakili oleh himpunan yang berbeda.
Menghitung Nilai-nilai Probabilitas
Yang kita perlukan adalah menghitung probabilitas 1 huruf benar, 2 huruf benar, dst. Dari diagram venn pada contoh, 1 huruf benar diwakili oleh bagian dari himpunan yang tidak beririsan, sedangkan 2 huruf benar diwakili bagian-bagian yang dibentuk oleh irisan 2 himpunan saja. Jadi probabilitas 2 huruf benar dihitung dari kata-kata di irisan-irisan 2 himpunan.
Untuk mendapatkan kombinasi himpunan-himpunan irisan tersebut, bahasa R menyediakan fungsi combn() yang dapat membuat matriks berisi kombinasi elemen dengan jumlah tertentu dalam sebuah vektor. Untuk lebih jelasnya, berikut contoh penggunaan fungsi ini:
Sintaks: combn(c(“C”,”R”,”A”,”N”,”E”),3)
Output:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] "C" "C" "C" "C" "C" "C" "R" "R" "R" "A"
[2,] "R" "R" "R" "A" "A" "N" "A" "A" "N" "N"
[3,] "A" "N" "E" "N" "E" "E" "N" "E" "E" "E"
Perhatikan bahwa tiap kolom mewakili kombinasi yang mungkin untuk 3 huruf dari huruf-huruf dalam “CRANE” seperti CRA, CRN, hingga ANE. Posisi huruf tidak berpengaruh di sini. Ini dapat digunakan untuk membuat irisan dengan 3 huruf tersebut dan menggabungkannya dengan irisan 3 huruf lainnya untuk menghitung probabilitas suatu kata mengandung 3 huruf benar.
Dengan demikian, fungsi yang saya buat memiliki alur penghitungan sebagai berikut:
- Membuat kombinasi huruf dengan jumlah tertentu dari suatu kata
- Membuat irisan dengan masing-masing kombinasi huruf. Ini dilakukan dengan melakukan filter pada daftar kata hanya dengan huruf-huruf dalam satu variasi kombinasi.
- Menghitung jumlah kata dan persentase hasil irisan dan menyimpannya dalam suatu data untuk data sekunder
- Menggabungkan (union) daftar kata hasil irisan.
- Menghitung jumlah kata dan persentase hasil penggabungan dan menyimpannya dalam suatu data untuk data primer
- Mengulang (looping) perintah kombinasi dengan jumlah huruf selanjutnya (dari 1 hingga jumlah huruf dalam kata)
Dalam fungsi prob_all() yang saya buat, parse() dan eval() digunakan kembali untuk membantu eksekusi perintah penggabungan.
Perlu diingat bahwa dalam fungsi ini terdapat mode “bebas” dan “posisi” yang menghasilkan nilai probabilitas berbeda. Tiap kata akan dievaluasi pada kedua mode ini untuk menghasilkan penilaian yang menyeluruh. Perbedaan kedua mode lebih pada cara setiap daftar kata disaring.
Pada kasus kata dengan huruf ganda, hasil kombinasi dengan combn() dan penggabungan persentase kata akan lebih sedikit, namun tidak akan menghasilkan error. Hal ini akan menjadi catatan untuk fungsi penghitungan nilai probabilitas keseluruhan.
Untuk detail tiap sintaks, saya tuliskan dalam comment.
# Fungsi menghitung semua probabilitas untuk
# semua jumlah kemunculan huruf benar
prob_all = function(kata_eval, asal_data, mode = "bebas"){
# Memastikan kata yang dievaluasi merupakan data frame
# agar bisa diolah lebih lanjut
if(!is.data.frame(kata_eval)){
kata_eval = data.frame(kata = c(kata_eval))
}
# Menyiapkan asal_data sesuai mode
# Pada mode posisi, asal_data perlu dipecah
# agar bisa di-filter sesuai posisi.
# Pada mode bebas, tidak perlu dipecah
if(mode == "posisi"){
# Memecah data kata sumber menjadi huruf per posisi
daftar_kata = pecah_kata(asal_data)
# Menyimpan data jumlah huruf per kata
colnum = ncol(daftar_kata)
# Indeks untuk membantu penyaringan
huruf_kata_idx = c(1:str_length(kata_eval))
}else if(mode == "bebas"){
# Agar penamaan variable tetap sama
daftar_kata = asal_data
# Memastikan tidak ada huruf yang sama
kata_eval = huruf_unik(kata_eval)
# Menyimpan data jumlah huruf per kata
colnum = str_length(kata_eval)
}
# Memecah kata evaluasi menjadi huruf per posisi
huruf_kata = pecah_kata(kata_eval)
# Pengecekan jika huruf lebih dari 7
if(colnum > 7){
return("Jumlah huruf terlalu banyak.")
}
# Untuk mengecek apakah jumlah huruf kata_eval
# sama dengan huruf-huruf di daftar kata sumber
if(str_length(asal_data[1,1])!= colnum){
# Pada mode bebas, beri peringatan jika
# huruf unik jumlahnya berbeda
if(mode == "bebas"){
cat("\nPeringatan dari prob_all():")
cat("\nJumlah huruf unik beda dengan daftar\n")
}else{
return("Jumlah huruf input kata
beda dengan daftar kata.")
}
}
# Menyimpan nilai jumlah data pada daftar kata
rsumber = nrow(daftar_kata)
# Menyiapkan data jumlah kata per huruf minimal
final_data1 = data.frame(set = character(),
jumlah = numeric(),
persen = double())
# Menyiapkan data jumlah kata per irisan
final_data2 = data.frame(set = character(),
jumlah = numeric(),
persen = double())
# Variabel pembantu looping kombinasi
l = 0
# Looping untuk menghitung variasi probabilitas
for(i in 1:length(huruf_kata)) {
# Membuat kombinasi huruf dalam kata
# yang bisa dibentuk dengan huruf
# sebanyak i
kombinasi = combn(huruf_kata,i)
# Pada mode posisi, untuk memastikan
# suatu huruf melakukan filter pada
# posisi yang tepat, diperlukan indeks.
# Ini bisa dilakukan dengan asumsi
# urutan kombinasinya sama dengan
# variabel "kombinasi"
if(mode == "posisi"){
idx = combn(huruf_kata_idx, i)
}
# Menyiapkan string yang akan dieksekusi
# untuk membuat list sebagai input untuk union
fun_str = "list("
# Looping untuk filter menggunakan huruf
# dari kombinasi lalu digabungkan dengan union
for(j in 1:ncol(kombinasi)){
# Untuk menyimpan data huruf-huruf beririsan
judul_set = ""
# Reset daftar kata ke sumber data
list_baru = daftar_kata
# Looping untuk filter huruf-huruf beririsan
for(k in 1:nrow(kombinasi)){
# Memilih huruf filter dari hasil kombinasi
huruf = kombinasi[k,j]
# Melakukan filter pada daftar kata sesuai mode
# Untuk mensimulasikan irisan, data hasil filter
# akan di-filter huruf selanjutnya yang
# masih satu variasi kombinasi
if(mode == "bebas"){
# Pada mode bebas, penyaringan menggunakan grepl
# untuk mencari kata yang mengandung huruf tertentu
list_baru = filter(list_baru,
grepl(huruf,
unlist(list_baru[1])))
}else if (mode == "posisi"){
# Pada mode posisi, penyaringan dilakukan
# dengan filter kolom
# idx_posisi memberikan informasi posisi
# huruf yang di filter
idx_posisi = idx[k,j]
list_baru = filter(list_baru,
unlist(list_baru[,idx_posisi]) ==
huruf)
}
# Pengaturan penamaan variasi kombinasi huruf
if(k != 1){
judul_set = paste0(judul_set, ".", huruf)
} else {
judul_set = paste0(judul_set,huruf)
}
}
# Jika kombinasi huruf beririsan selesai,
# tambah nilai l
l = l+1
# Menghitung probabilitas jumlah kata hasil irisan
# terhadap total kata di daftar kata
jumlah_set = nrow(list_baru)
persen_set = round(100*jumlah_set/rsumber,
digits = 2) %>%
format(nsmall = 2) %>%
paste0("%")
# Memasukkan judul, jumlah, dan persentase irisan
# ke dalam data
final_data2[l,] = c(judul_set, jumlah_set, persen_set)
# Menyimpan data kata hasil irisan
# ke dalam data baru
hasil_iris = paste0("iris_",j)
# Pada mode bebas, data hasil irisan
# langsung dimasukkan
# Pada mode posisi, data digabungkan dulu
# jadi satu kata
if(mode == "bebas"){
assign(hasil_iris, list_baru)
} else if (mode == "posisi"){
merge_str = unlist(list_baru[,1])
for(m in 2:colnum){
merge_str = paste(merge_str, unlist(list_baru[,m]))
}
assign(hasil_iris, merge_str)
}
# Update teks sintaks untuk list
fun_str = ifelse(j == ncol(kombinasi),
paste0(fun_str, hasil_iris, ")"),
paste0(fun_str, hasil_iris," , "))
}
# Mengeksekusi perintah teks untuk membuat list
list_union = eval(parse(text = fun_str))
# Mengeksekusi perintah union untuk menggabungkan
# semua himpunan irisan yang dibentuk oleh
# jumlah huruf yang sama tanpa menghitung
# double data yang sama
hasil_union = Reduce(union, list_union) %>%
data.frame() # memastikan output berupa data frame
# Menghitung probabilitas jumlah kata hasil union
# terhadap total kata di daftar kata
jumlah_set_union = nrow(hasil_union)
persen_set_union = round(100*jumlah_set_union/rsumber,
digits = 2) %>%
format(nsmall = 2) %>%
paste0("%")
# Memasukkan judul, jumlah, dan persentase union
# ke dalam data
final_data1[i,] = c(paste("minimal ",i," huruf"),
jumlah_set_union,
persen_set_union)
}
# Menyimpan kedua data dalam list agar bisa
# dikirim ke luar fungsi
final_data = list(final_data1, final_data2)
# Mengirimkan output fungsi
return(final_data)
}Kita lihat hasil fungsi ini untuk mengevaluasi kata “CRANE” dengan mode “bebas” (default) melalui sintaks berikut: prob_all("CRANE", exclude_list)
(Hasil berdasarkan data pada 16 Juni 2023)
Hasil:
[[1]]
set jumlah persen
1 minimal 1 huruf 1389 87.69%
2 minimal 2 huruf 881 55.62%
3 minimal 3 huruf 282 17.80%
4 minimal 4 huruf 24 1.52%
5 minimal 5 huruf 1 0.06%
[[2]]
set jumlah persen
1 C 308 19.44%
2 R 556 35.10%
3 A 604 38.13%
4 N 394 24.87%
5 E 715 45.14%
6 C.R 99 6.25%
7 C.A 117 7.39%
8 C.N 60 3.79%
9 C.E 125 7.89%
10 R.A 204 12.88%
11 R.N 91 5.74%
12 R.E 287 18.12%
13 A.N 146 9.22%
14 A.E 234 14.77%
15 N.E 158 9.97%
16 C.R.A 30 1.89%
17 C.R.N 10 0.63%
18 C.R.E 44 2.78%
19 C.A.N 21 1.33%
20 C.A.E 39 2.46%
21 C.N.E 21 1.33%
22 R.A.N 31 1.96%
23 R.A.E 85 5.37%
24 R.N.E 40 2.53%
25 A.N.E 39 2.46%
26 C.R.A.N 4 0.25%
27 C.R.A.E 9 0.57%
28 C.R.N.E 3 0.19%
29 C.A.N.E 5 0.32%
30 R.A.N.E 7 0.44%
31 C.R.A.N.E 1 0.06%Bagian [[1]] merupakan data primer yang menampilkan probabilitas masing-masing jumlah huruf benar. Bagian [[2]] merupakan data sekunder yang menampilkan probabilitas per irisan yang kira-kira isinya sama dengan yang kita lihat di pada diagram venn namun dilengkapi dengan persentase terhadap jumlah kata dalam daftar kata.
Karena outputnya berupa list, kita dapat merujuk pada nilai output tertentu, misalnya persentase minimal 3 huruf benar, dengan menggunakan indeks melalui sintaks seperti berikut:
prob_all("CRANE", exclude_list)[[1]][3,3]Hasil:
[1] "17.80%"Sintaks di atas mengambil entri di kolom ke-3 dari baris ke-3 pada data pertama yang memuat persentase probabilitas kemunculan 3 huruf benar. Tentu saja kita bisa juga menyimpan output fungsi dalam variabel kemudian memanggil nilai yang kita inginkan melalui indeks. Ini akan berguna pada tahap selanjutnya dari validasi ini.
Menghubungkan Semuanya: Mencari Kandidat Kata Terbaik, Menghitung Nilainya, dan Menemukan Kata Terbaik
Sekarang kita akan menggabungkan fungsi-fungsi pencarian kata dari tahap 3 dengan fungsi-fungsi validasi nilai pada tahap 4 dalam satu fungsi. Fungsi ini juga digunakan untuk melihat metode terbaik dalam pencarian kata terbaik.
Perlu diingat bahwa seluruh kata kandidat, baik yang ditemukan lewat tebakan_cara1() (bebas posisi) maupun tebakan_cara2A() dan tebakan_cara2B() (tepat posisi) akan dinilai probabilitasnya dalam 2 mode: nilai probabilitas huruf di posisi bebas dan di posisi tepat.
Namun kita perlu mencatat tiap cara suatu kata kandidat di temukan pada data akhir. Karenanya, saya membuat fungsi keterangan_cara() yang menggunakan perintah deparse(substitute()) untuk mengambil nama variabel dari suatu input.
# Fungsi tambahan untuk mencatat cara yang digunakan
# untuk menemukan kata tebakan
# hanya berfungsi kalau daftar kata tebakan dimasukkan
# dalam variable data yang jadi parameter fungsi ini
# Output berupa data 2 kolom (kata dan cara)
keterangan_cara = function(data_eval){
# Menyiapkan data output
hasil = data.frame(kata = character(), cara = character())
# Memberikan data di kolom cara untuk masing-masing kata
# dalam data_eval
# Fungsi deparse dan substitute akan sama menghasilkan
# teks/string dari variabel yang dimasukkan
# jadi parameter data_eval
# ex, jika fungsi ini dipanggil dengan:
# keterangan_cara(grup_1_all)
# maka hasil deparse(substitute(data_eval))
# adalah "grup_1_all"
for(i in 1:nrow(data_eval)){
hasil[i,] = c(data_eval[i,1],deparse(substitute(data_eval)))
}
# Mengirimkan data hasil
return(hasil)
}Untuk penggunaan dan outputnya akan kita coba langsung perlihatkan bersamaan dengan fungsi utama nilai_akhir().
Pada bagian pertama dari fungsi nilai_akhir(), semua cara akan dicoba untuk menghasilkan kata kandidat. Ada 3 cara untuk menghasilkan kata kandidat dan masing-masing cara akan menggunakan exclude_list dan all_wordle_list sebagai sumber daftar kata-nya. Total ada 6 grup cara yang masing-masing menghasilkan 1-3 kata. 2 cara berbeda mungkin menghasilkan kata yang sama. Grup cara ini akan dicatat menggunakan fungsi keterangan_cara() di atas. Hasil bagian ini adalah tabel berisi daftar kata kandidat beserta keterangan grup cara yang menghasilkannya.
Setiap kata akan divisualisasikan dan dievaluasi nilainya baik pada mode “bebas” maupun “posisi”. Hasil visualisasi diagram venn akan langsung disimpan dalam file PNG. Hasil evaluasi nilai probabilitas dalam kedua mode dan total persentase keseluruhannya akan disimpan dalam sebuah tabel data. Tabel data ini kemudian diurutkan berdasarkan kolom nilai probabilitas total, 1 huruf bebas posisi, 1 huruf tepat posisi, 3 huruf bebas posisi, dan 3 huruf tepat posisi.
Harap dicatat bahwa penentuan 3 huruf bebas/tepat posisi ini berdasarkan jumlah huruf yang dianggap setengah dari panjang kata. Parameter ini sebenarnya tidak terlalu berpengaruh pada urutan. Total probabilitas tetap memiliki pengaruh paling besar.
Pada kata dengan huruf ganda, jumlah kolom hasil dari prob_all() mode “bebas” akan lebih sedikit karena huruf unik nya yang lebih sedikit. Agar jumlah kolomnya sama, hasil tersebut akan ditambah dengan kolom bernilai “0”.
Dengan demikian, fungsi nilai_akhir() ditulis sebagai berikut:
# Fungsi mencari seluruh kandidat kata terbaik
# dan mengevaluasi nilai probabilitasnya
nilai_akhir = function(daftar_kata,
sumber_data,
persentil = 0.954){
# Menyiapkan data untuk menampung daftar
# kata hasil tebakan dari semua cara
kata_eval = data.frame(kata = character())
# Mencari kata kandidat dari berbagai cara
# (bebas dan tepat posisi) dan menggunakan
# exclude_list dan all_wordle_list
# (daftar_kata dan sumber_data)
# Bebas posisi
grup_1_all = tebakan_cara1(daftar_kata, sumber_data)
grup_1_ex = tebakan_cara1(daftar_kata, daftar_kata)
# Tepat posisi versi A (urutan probabilitas)
grup_2A_all = tebakan_cara2A(daftar_kata, sumber_data)
grup_2A_ex = tebakan_cara2A(daftar_kata, daftar_kata)
# Tepat posisi versi B (persentil)
grup_2B_all = tebakan_cara2B(daftar_kata,
sumber_data, persentil)
grup_2B_ex = tebakan_cara2B(daftar_kata,
daftar_kata, persentil)
# Memberikan keterangan cara untuk tiap kata
# Output berupa data yang mengandung kata
# serta keterangan cara tebakan
grup_1_all = keterangan_cara(grup_1_all)
grup_1_ex = keterangan_cara(grup_1_ex)
grup_2A_all = keterangan_cara(grup_2A_all)
grup_2A_ex = keterangan_cara(grup_2A_ex)
grup_2B_all = keterangan_cara(grup_2B_all)
grup_2B_ex = keterangan_cara(grup_2B_ex)
# Menggabungkan daftar kata kandidat dari semua cara
# Di sini menggunakan union_all agar kata
# yang sama dari cara yang berbeda
# tetap bisa ditampilkan
kata_eval = Reduce(union_all, list(
grup_1_all, grup_1_ex,
grup_2A_all, grup_2A_ex,
grup_2B_all, grup_2B_ex))
# Menampilkan daftar kata yang akan dievaluasi
print(kata_eval)
# Menyiapkan variabel untuk menampung
# data akhir
tabel_hasil = data.frame()
# Menyimpan data panjang kata dalam daftar
colnum = str_length(sumber_data[1,1])
# Mengevaluasi semua kata tebakan
# menggunakan dua mode penghitungan
# memasukkan hasilnya pada data
# Juga membuat visualisasi diagram venn
# untuk masing-masing metode
for(i in 1:nrow(kata_eval)){
# Membuat visualisasi diagram venn
# dari kata yang dievaluasi pada
# posisi huruf bebas
# OUtput langsung jadi file PNG
ggsave(
paste0("venn_",
kata_eval[i,1],
"_bebas.png"),
gambar_venn(kata_eval[i,1],
daftar_kata, "bebas"),
width = 3.5,
height = 3.5,
dpi = 240
)
# Menghitung semua probabilitas kata
# pada posisi huruf bebas
# Hanya mengambil data primer dari
# fungsi prob_all() kolom 3 (data persen)
# Karena datanya berupa string
# dan ada tanda %, data diolah dulu
# untuk menghapus tanda %,
# convert ke numeric dan transpose
# agar data menjadi satu baris
prob_bebas = prob_all(kata_eval[i,1],
daftar_kata,
"bebas")[[1]][3] %>%
unlist() %>% # agar bisa str_remove()
str_remove("%") %>% # menghapus %
as.numeric() %>% # convert data
t() %>% # transpose
data.frame() # agar dapat diolah lebih lanjut
# Jika huruf unik lebih sedikit dari
# panjang kata dalam daftar, tambahkan
# kolom agar sesuai dengan
# jumlah kolom yang seharusnya
# Ini hanya diperlukan saat evaluasi
# nilai mode bebas
if(ncol(prob_bebas)!=colnum){
idx_awal = ncol(prob_bebas)+1
for(j in idx_awal:colnum){
prob_bebas[1,idx_awal] = 0
}
}
# Memberikan prefiks pada nama kolom
names(prob_bebas) = paste0("beb_",
1:ncol(prob_bebas))
# Selanjutnya melakukan hal yang sama
# pada posisi huruf tepat
ggsave(
paste0("venn_",
kata_eval[i,1],
"_posisi.png"),
gambar_venn(kata_eval[i,1],
daftar_kata, "posisi"),
width = 3.5,
height = 3.5,
dpi = 240
)
prob_posisi = prob_all(kata_eval[i,1],
daftar_kata,
"posisi")[[1]][3] %>%
unlist() %>%
str_remove("%") %>%
as.numeric() %>%
t() %>%
data.frame()
names(prob_posisi) = paste0("pos_",
1:ncol(prob_posisi))
# Menggabungkan data dari posisi bebas
# dengan posisi tepat
gabungan = merge(prob_bebas , prob_posisi)
# Menjumlahkan semua nilai persen
# Ingat, data gabungan hanya 1 baris
total_gabung = rowSums(gabungan)
# Menggabungkan data kata dan keterangan cara
# dengan gabungan data persentase
# dan dengan total jumlah persentase
# Perlu diingat bahwa merge() hanya bisa
# menggabungkan 2 data
gabungan_baru =
merge(kata_eval[i,],
merge(gabungan,
c(total_gabung))) # harus vektor
# Memasukkan data gabungan baru ke
# tabel_hasil, baris per baris.
# Karena tabel_hasil awalnya kosong,
# baris pertama tidak pakai indeks
if(i == 1){
tabel_hasil = gabungan_baru
} else {
tabel_hasil[i,] = gabungan_baru
}
}
# Jumlah huruf pada kata
jumlah_huruf = str_length(kata_eval[1,1])
# Nilai tengah jumlah huruf sebagai
# acuan salah satu parameter urutan
# pada kata 5 huruf, tengah adalah 3
tengah = (jumlah_huruf%/%2)+(jumlah_huruf%%2)
# Jumlah kolom tabel_hasil
colnum = ncol(tabel_hasil)
# Mengganti nama kolom total
names(tabel_hasil)[colnum] = "total"
# Menyusun data hasil akhir berdasarkan nilai total,
# beb_1, pos_1, beb_tengah, dan pos_tengah
tabel_hasil = arrange(tabel_hasil,
across(c(total, beb_1, pos_1,
paste0("beb_",tengah),
paste0("pos_",tengah)),
desc))
# Menyeragamkan format data-data persen
tabel_hasil[,3:colnum] =
format(unlist(tabel_hasil[,3:colnum]), nsmall=2) %>%
paste0("%")
# Mengirimkan hasil
return(tabel_hasil)
}Dengan memasukkan exclude_list sebagai parameter daftar_kata, all_wordle_list sebagai sumber_data, dan nilai persentil default serta data hasil nilai disimpan pada variabel (misalnya kita beri nama hasil_akhir), maka sintaks dapat ditulis sebagai berikut:
(Hasil berdasarkan data pada 16 Juni 2023)
Sintaks:
hasil_akhir = nilai_akhir(exclude_list, all_wordle_list)Hasil:
(Output hasil dari perintah print() atau cat() pada fungsi masing-masing tidak ditampilkan di sini. Untuk hasil dari fungsi nilai_akhir() kita akan fokuskan pada diagram venn dan tabel nilai probabilitas.)
Output Diagram Venn:
“ARIEL”
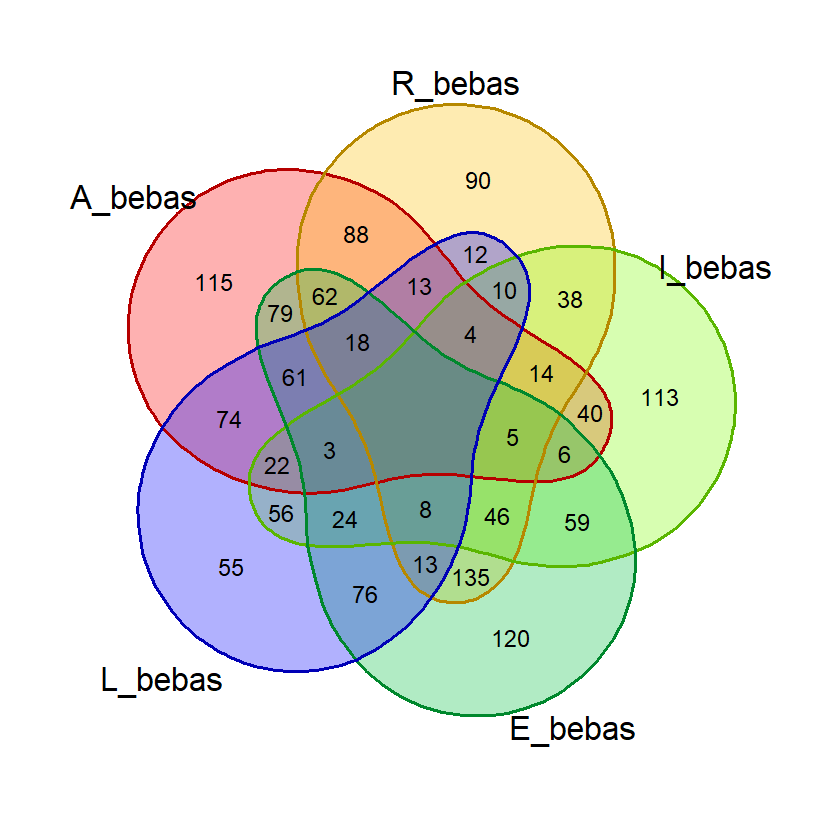
“RAILE”
“LATER”

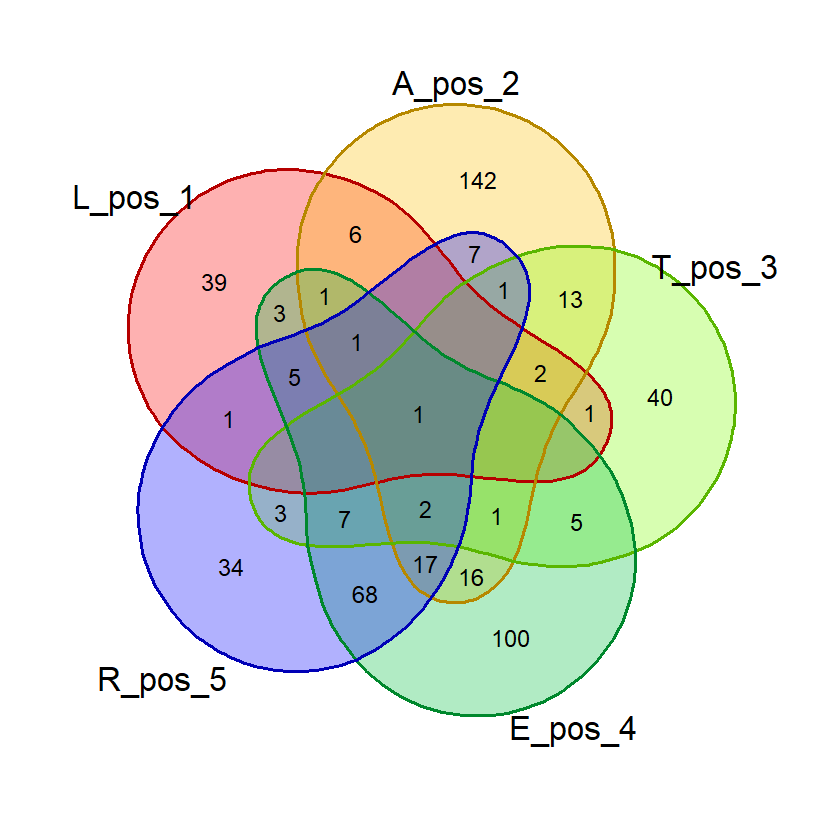
“ALERT”


”SAREE”
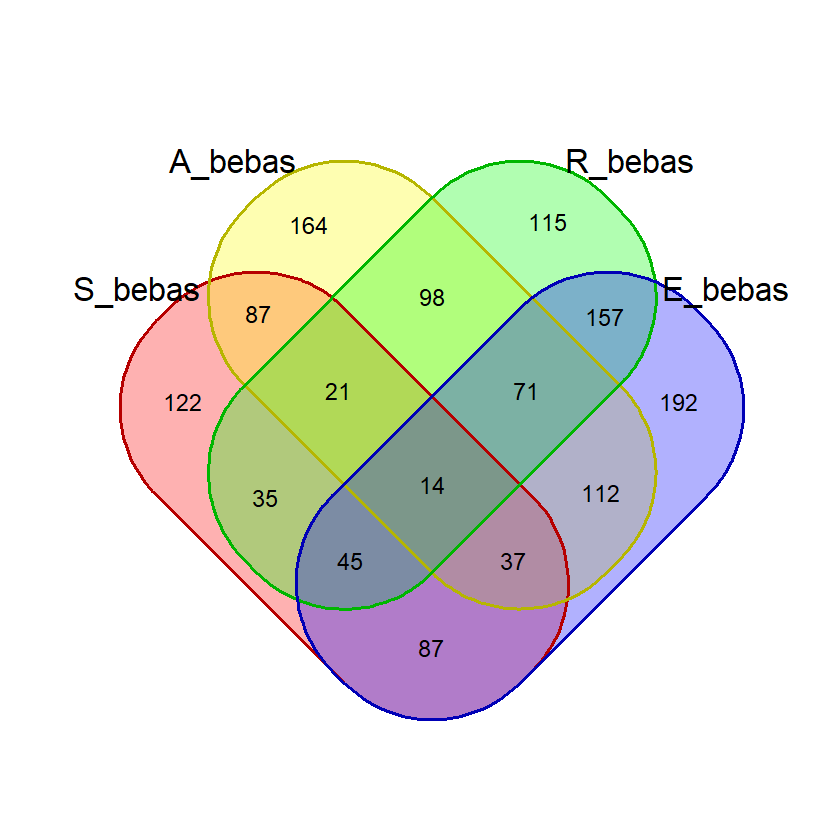
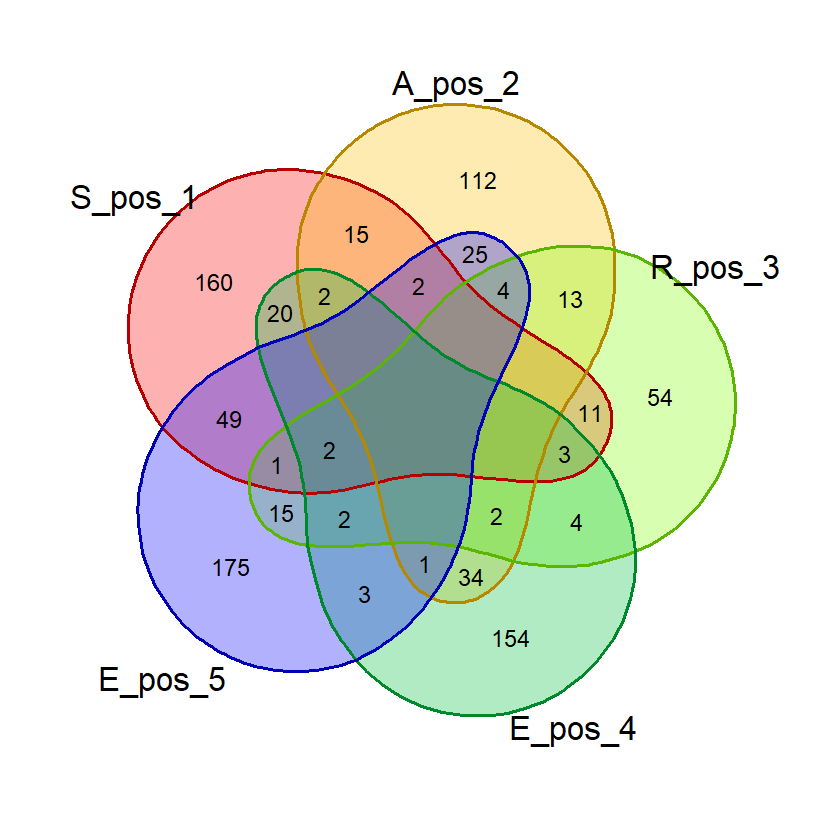
“SAYEE”

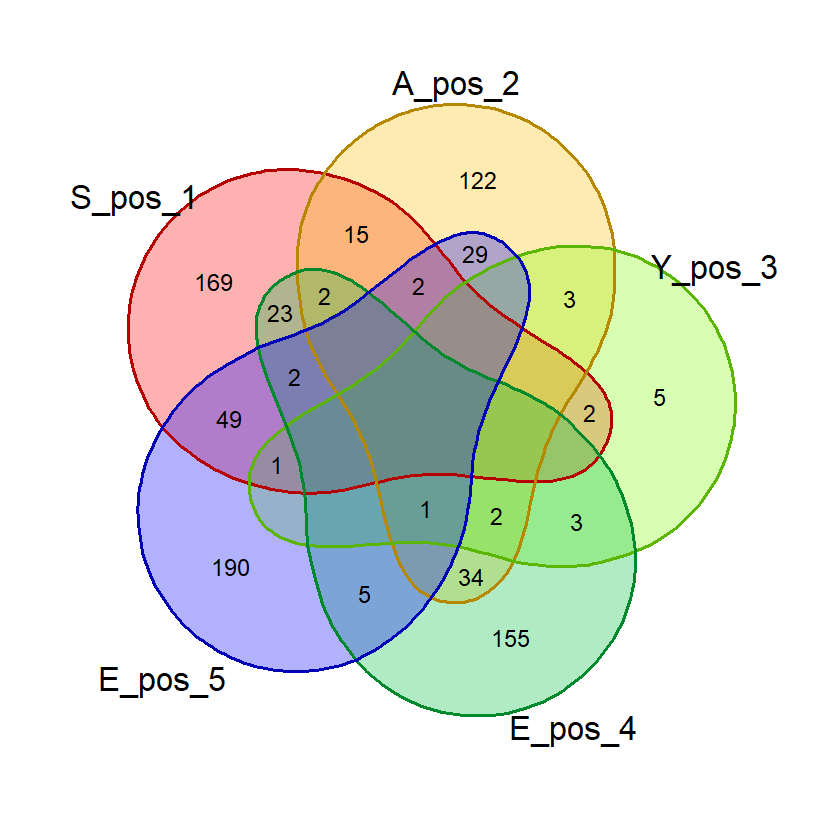
“SCREE”

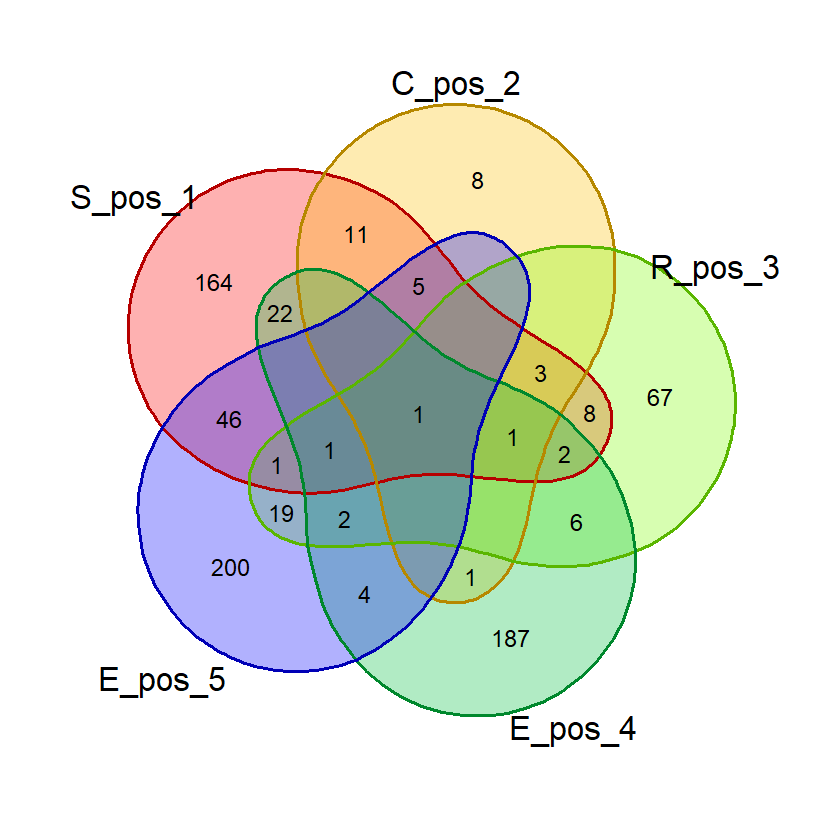
“SPREE”

“SAINE”

“CRANE”
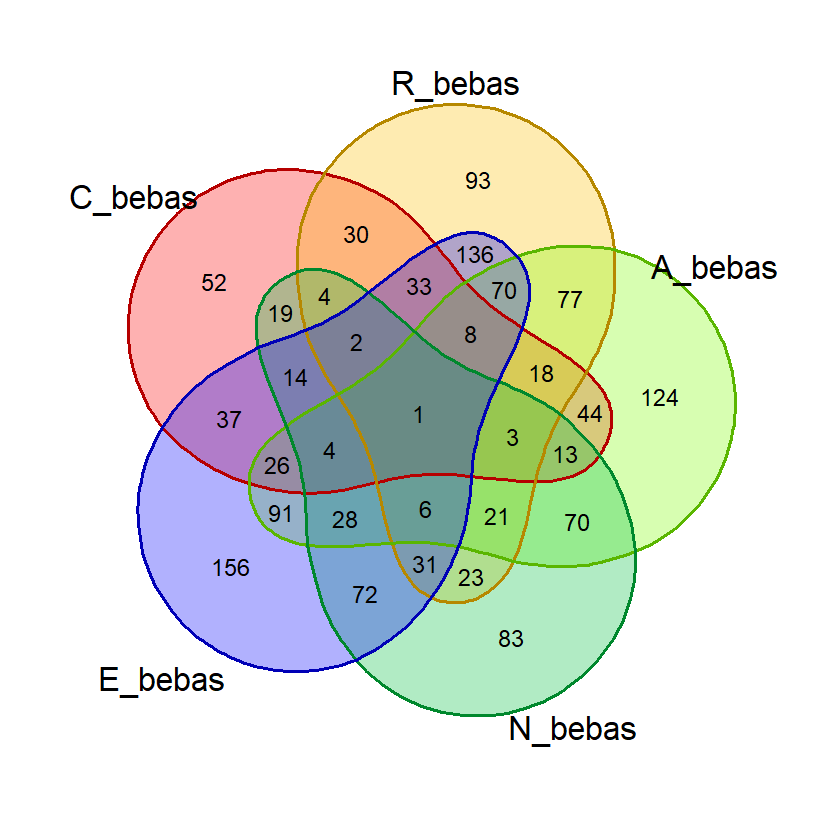
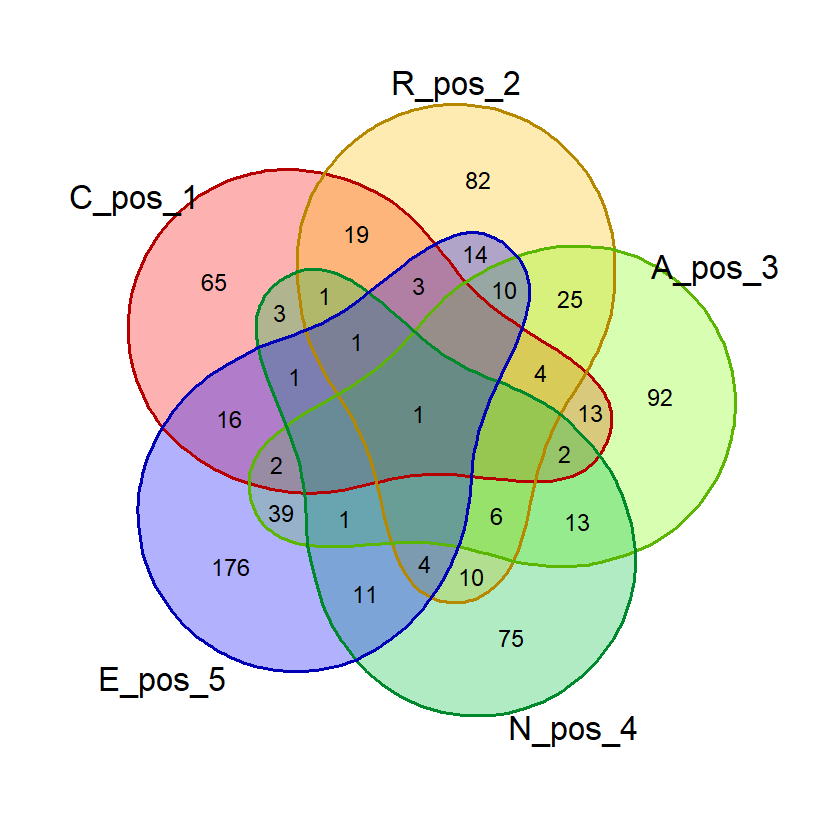
“CRINE”
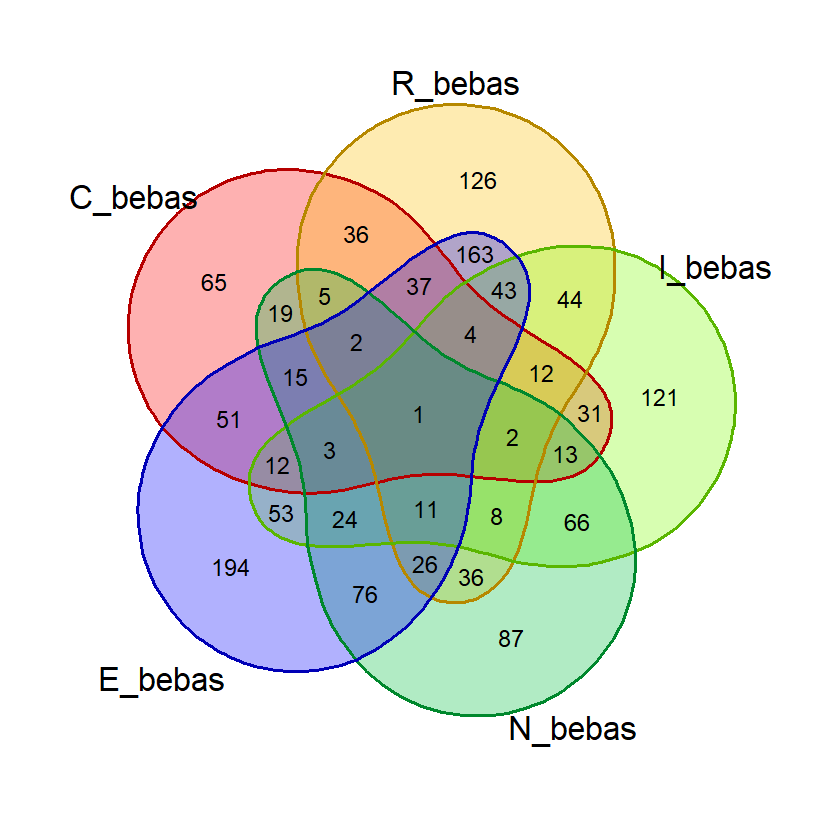
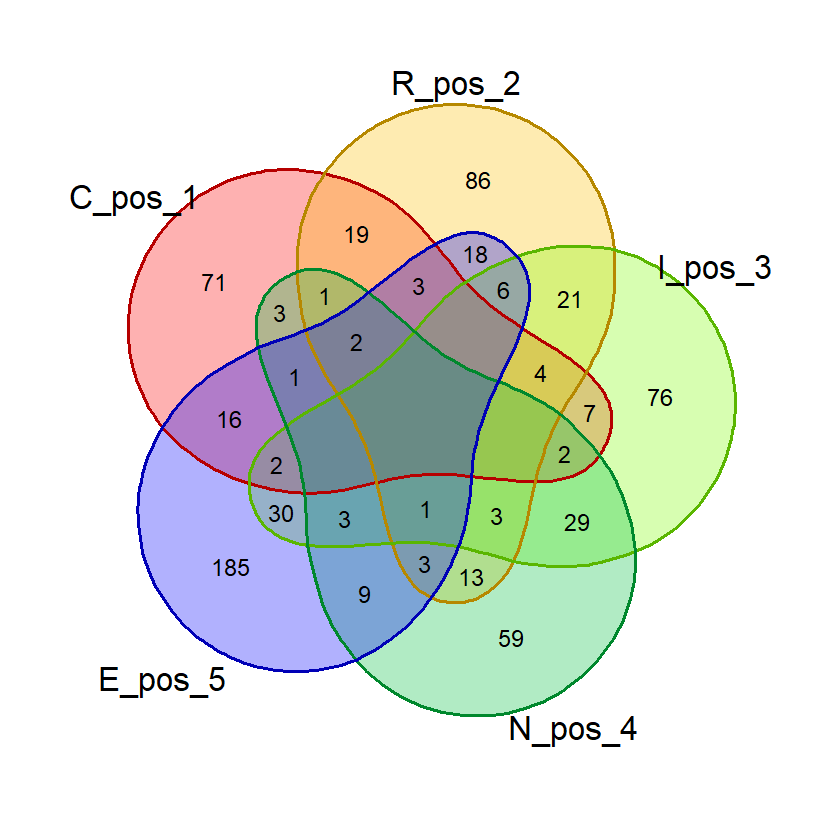
(Catatan: “CRANE” sebenarnya muncul dua kali, karena muncul dari dua cara, namun filenya tertimpa karena namanya sama. Ini tidak masalah karena diagram venn-nya akan sama dan menampilkan keduanya dalam konteks ini tidak berpengaruh pada analisis.)
Output data akhir:
kata cara beb_1 beb_2 beb_3 beb_4 beb_5 pos_1 pos_2
1 SAINE grup_2B_all 91.41% 56.50% 15.21% 1.58% 0.00% 50.88% 14.33%
2 RAILE grup_1_all 92.11% 60.98% 19.51% 2.40% 0.00% 44.13% 9.66%
3 ARIEL grup_1_all 92.11% 60.98% 19.51% 2.40% 0.00% 40.66% 7.77%
4 CRANE grup_2B_all 87.69% 55.62% 17.80% 1.52% 0.06% 43.50% 12.56%
5 CRANE grup_2B_ex 87.69% 55.62% 17.80% 1.52% 0.06% 43.50% 12.56%
6 LATER grup_1_ex 90.59% 60.16% 20.64% 2.90% 0.13% 32.58% 10.16%
7 SAREE grup_2A_all 85.67% 48.23% 11.87% 0.88% 0.00% 54.48% 13.13%
8 ALERT grup_1_ex 90.59% 60.16% 20.64% 2.90% 0.13% 30.37% 5.62%
9 CRINE grup_2B_all 87.50% 50.06% 13.76% 1.45% 0.06% 42.49% 12.37%
10 SAYEE grup_2A_all 85.61% 38.57% 6.19% 0.06% 0.00% 51.39% 10.92%
11 SCREE grup_2A_ex 81.44% 38.38% 7.77% 0.38% 0.00% 47.92% 8.40%
12 SPREE grup_2A_ex 78.79% 35.80% 8.02% 0.69% 0.00% 47.66% 9.41%
pos_3 pos_4 pos_5 total
1 2.08% 0.06% 0.00% 232.05%
2 1.01% 0.06% 0.00% 229.86%
3 1.07% 0.00% 0.00% 224.50%
4 2.27% 0.13% 0.06% 221.21%
5 2.27% 0.13% 0.06% 221.21%
6 2.40% 0.25% 0.06% 219.87%
7 1.20% 0.13% 0.00% 215.59%
8 1.01% 0.06% 0.06% 211.54%
9 1.96% 0.19% 0.00% 209.84%
10 0.63% 0.06% 0.00% 193.43%
11 1.01% 0.19% 0.06% 185.55%
12 1.07% 0.13% 0.06% 181.63%(Catatan: Hasil ini tidak keluar setelah sintaks dieksekusi karena hasilnya dimasukkan dalam variable. Output ini ditampilkan setelah memanggil variable hasil_akhir pada konsol.)
5 – Analisis Akhir
Dari data di atas, kita menemukan beberapa hal:
- “SAINE” adalah kata terbaik berdasarkan penghitungan total probabilitas. Meski demikian, kata tersebut bukan yang paling tinggi dalam masing-masing urutan nilai probabilitas.
- Kata yang berasal dari fungsi
tebakan_cara2B()dantebakan_cara1()dengan sumber data all_wordle_list mendominasi 5 kata teratas. tebakan_cara2A()menghasilkan kata dengan nilai rendah karena memiliki huruf ganda.- Kata dari
all_wordle_listsecara umum memberikan nilai yang lebih tinggi.
6 – Pengujian
Kata terbaik sebaiknya diuji dalam 7 hari ke depan untuk membuktikan kemampuannya dalam mempermudah permainan. Namun, karena tiap hari ada kata yang keluar sebagai jawaban, kata terbaik mungkin akan berubah setiap hari meski sejauh ini masih sama.
Sementara akan dilakukan pengujian menggunakan kata “SAINE” sebagai tebakan awal dan kata lain dari hasil_akhir dan data-data lain dalam analisis untuk membantu tebakan selanjutnya. Artikel ini akan diupdate dengan hasil-hasil pengujian selama 7 hari.
Kesimpulan
Pertanyaan pada bagian Pendahuluan dan Target dari tulisan ini adalah ‘Apa kata terbaik sebagai tebakan awal pada Wordle?’
Jawabannya adalah “SAINE” yang meski tidak ada pada daftar jawaban namun akan membantu menemukan huruf yang benar dan mengeliminasi lebih banyak kata jawaban jika tidak benar.
Ide Pengembangan
- Mengevaluasi semua kata pada Wordle (
all_wordle_list) dengan menggunakan fungsiprob_all()untuk mendapatkan perbandingan yang lebih menyeluruh dan hasil yang lebih akurat. Ini memerlukan resource komputasi yang lebih besar. Mungkin menggunakan layanan cloud computing atau parallel/grid computing dapat membantu. - Menggunakan kode-kode dalam analisis pada tiruan game Wordle pada bahasa lain, misalnya Katla (Bahasa Indonesia) dan Keclap (Bahasa Sunda). Perbedaan analisisnya seharusnya hanya pada tahap pengumpulan data saja, tapi tidak menutup kemungkinan ada hal-hal menarik lain yang bisa dianalisis.
- Menguji analisis pada tiruan Wordle yang menggunakan jumlah huruf yang berbeda.
- Saat melakukan analisis, saya menyadari jika Wordle memiliki fitur Wordle Bot yang menganalisis seberapa akurat tebakan kita. Mencoba meniru cara kerja Wordle Bot ini dan membandingkannya dapat menjadi ide pengembangan yang menarik.
- Mengembangkan tool untuk menghitung probabilitas kata terbaik jika tebakan sudah dilakukan. Misalnya, jika dari tebakan pertama diketahui huruf-huruf yang ada, tidak ada, dan salah posisi, tool ini bisa memberikan kata terbaik untuk tebakan selanjutnya.
- Beberapa sumber lain yang mencoba mencari kata terbaik untuk Wordle menggunakan information theory sebagai dasar analisis. Mencoba analisis baru menggunakan teori ini dapat menjadi ide pengembangan.
tebakan_2A()menghasilkan kata dengan nilai rendah karena menghasilkan huruf ganda. Membuat algoritma untuk mencegah fungsi tersebut menghasilkan huruf ganda mungkin dapat membantu fungsi tersebut menghasilkan kata yang lebih baik. Selain itu, ide-ide untuk mencari kata tebakan lainnya perlu dieksplorasi.
Penutup
Secara umum, proyek pribadi ini cukup melatih kemampuan R saya. Saya berterima kasih terhadap Arthur Holtz yang artikelnya menjadi pemantik untuk saya memulai proyek ini meski perkembangan analisisnya jadi melenceng dari yang dibuat olehnya.
Pelajaran yang saya ambil dari proyek ini lebih ke membiasakan diri dengan algoritma komputasi yang agak matematis daripada memahami cara kerja bahasa R. Untuk analisis personal dan bersifat independen, R masih menarik. Tapi menguasai Python sepertinya lebih memberikan kesempatan yang luas.
Jadi kedepannya mungkin saya akan lebih menggunakan Python, disamping juga membiasakan mengulik SQL dan github… jika saya tidak lanjut mengasah kemampuan game development.